1. Wprowadzenie
W szeroko pojêtym zarz¹dzaniu przedsiêbior-stwem mamy do czynienia z wieloma zadaniami, które wi¹¿¹ siê z ograniczon¹ wiedz¹ i niepew-noci¹, dotycz¹c¹ przebiegu zdarzeñ oraz dzia³a-nia zarz¹dzanymi obiektami. Wynika to z tempa, zakresu, zasiêgu, g³êbokoci i szybkoci rozcho-dzenia siê zmian w zglobalizowanej gospodarce, która jest otoczeniem pozornie lokalnych przed-siêwziêæ [13], a tak¿e jest efektem zjawisk natu-ralnych, które wci¹¿ zostaj¹ nieposkromione dla umys³ów badaczy. Mo¿emy zatem wyró¿niæ nie-pe³noæ informacji, wynikaj¹c¹ z niewiedzy ludzkiej, zwan¹ niepewnoci¹ subiektywn¹, a tak¿e niepewnoæ obiektywn¹, która wynika z charakterystyki analizowanych procesów. Aby móc odkryæ i usystematyzowaæ wiedzê obar-czon¹ wymienionymi zagadnieniami, w literatu-rze spotyka siê modelowanie z wykorzystaniem logiki rozmytej [12, 19].
Jednoczenie, w wielu sytuacjach ekonomiczno-decyzyj-nych w przedsiêbiorstwie, mamy do czynienia z niepewno-ci¹ wynikaj¹c¹ z losowoci, np. niepewnoæ wartoci pa-rametrów zjawisk spo³ecznych (np. zachorowalnoæ wród pracowników), ekonomicznych (np. wysokoæ wskani-ków gie³dowych) czy zjawisk geologicznych (np. prêdkoæ i kierunek wiatru mierzony podczas szacowania op³acalno-ci inwestycji w elektrownie wiatrowe), które wykorzysty-wane s¹ do szeregu procesów podejmowania decyzji w przedsiêbiorstwach w skali zarz¹dzania operacyjnego, taktycznego lub strategicznego. Do modelowania takich procesów wykorzystywane s¹ g³ównie metody matema-tyczne z uwzglêdnieniem teorii prawdopodobieñstwa. Zdaje siê byæ naturalnym, i¿ ³¹cz¹c obie metody analizowa-nia zagadnieñ - teoriê logiki rozmytej i teoriê prawdopodo-bieñstwa, mo¿emy w sposób pe³ny opisaæ niepewnoæ pro-blemów rzeczywistych zachodz¹cych w procesach przed-siêbiorstwa (rys. 1). Tak te¿ powsta³a koncepcja systemu wnioskuj¹cego z probabilistyczno-rozmyt¹ baz¹ wiedzy [3], której metodologiê modelowania i wnioskowania przedstawiono m.in. w pracach [21, 23].
W omawianym systemie wiedza lingwistyczna jest zawarta w regu³ach postaci IF-THEN z wagami, stanowi¹cymi brze-gowe i warunkowe prawdopodobieñstwo zdarzeñ rozmy-tych znajduj¹cych siê w poprzedniku i nastêpniku regu³. Z za³o¿enia system rozmyty ma pozwalaæ na uproszczone odtworzenia skomplikowanego problemu badawczego. Jed-nak¿e, przy wielu zmiennych systemu oraz zidentyfikowanej du¿ej iloci zbiorów rozmytych, utworzenie wspomnianego modelu cechuje wysoka z³o¿onoæ obliczeniowa. Ponadto, bior¹c pod uwagê ca³kowity rozk³ad prawdopodobieñstwa
zdarzeñ rozmytych, iloæ regu³ elementarnych bazy wiedzy wynosi N m, gdzie N stanowi liczbê zmiennych modelu,
m liczbê zbiorów rozmytych zmiennej (przy za³o¿eniu jed-nakowej iloci zbiorów rozmytych dla ka¿dej zmiennej). Du¿a liczba regu³ ma wp³yw nie tylko na czas identyfikacji modelu, trudnoci wnioskowania przy u¿yciu utworzonej bazy wiedzy, jak równie¿ ewentualn¹ implementacjê w obiek-cie rzeczywistym. W artykule zostanie pokazana mo¿liwoæ wykorzystania idei wyszukiwania regu³ asocjacji (jednej z metod data mining) do pozyskiwania parametrów modelu dla systemu wnioskuj¹cego z probabilistyczno-rozmyt¹ baz¹ wiedzy. Algorytm pozwoli bezporednio znaleæ wiarygod-ne regu³y rozmyte wraz z wagami, które bêd¹ stanowiæ pod-stawê do wnioskowania w oparciu o budowany model. 2. Koncepcja systemu wnioskuj¹cego z
probabilistycz-no-rozmyt¹ baz¹ wiedzy
Rozmyte systemy wnioskuj¹ce stanowi¹ systemy z bazami wiedzy (ang. knowledge-based systems), w których wyko-rzystane jest podejcie lingwistyczne [26] podczas modelo-wania i wnioskomodelo-wania, zwanego równie¿ modelowaniem i wnioskowaniem rozmytym. Stosuj¹c podejcie lingwi-styczne, zbiory rozmyte uto¿samiane s¹ ze zmiennymi lin-gwistycznymi, których wartoci odpowiadaj¹ pewnym ka-tegoriom jêzyka naturalnego i s¹ reprezentowane przez s³o-wa lub stwierdzenia (np. wysoki, redni, niski koszt albo wystarczaj¹ca, niewystarczaj¹ca jakoæ) [15]. Ocena s³owna pozwala na opisanie niepewnej wiedzy o analizo-wanych zmiennych, a jednoczenie jest znaczeniowo zale¿-na od rzeczywistych obszarów.
Katarzyna RUDNIK, Anna WALASZEK-BABISZEWSKA
ROZMYTY SYSTEM WNIOSKUJ¥CY O MODELU BAZUJ¥CYM NA
REGU£ACH ASOCJACJI
Rys. 1. Koncepcja pe³nego opisu niepewnoci procesów zachodz¹cych w przedsiêbiorstwie
W klasycznym ujêciu logiki rozmytej zbiór rozmyty A (ang. fuzzy set), zdefiniowany w niepustej przestrzeni À, jest okre-lony przez funkcjê charakterystyczn¹ zwan¹ funkcj¹ przy-nale¿noci mA (ang. membership function) w formie [26]:
(1) gdzie [0,1] oznacza przedzia³ liczb rzeczywistych od 0 do 1. Omawiany system wnioskuj¹cy wykorzystuje analogiczne podejcie do definicji zbiorów rozmytych, jednak¿e za-miast funkcji przynale¿noci stosuje siê sta³e stopnie przy-nale¿noci, zdefiniowane dla roz³¹cznych przedzia³ów wartoci zmiennych (por. (8) i rys. 3). Zasadnoæ stosowa-nia stopni przynale¿noci podczas modelowastosowa-nia w oma-wianym systemie zamieszczono w [4]. Dyskretyzacja prze-strzeni wartoci zmiennych wp³ywa nieznacznie na struk-turê modelu, jednak¿e skraca czas generowania regu³ oraz wnioskowania. D³u¿szy czas generowania regu³ i wniosko-wania dla bazy danych definiowanej za pomoc¹ funkcji przynale¿noci, wynika z niemo¿noci wprowadzenia zwektoryzowanych obliczeñ, co ma znaczenie przy imple-mentacji systemu w rodowisku obliczeniowym Matlab. System wnioskuj¹cy z probabilistyczno-rozmyt¹ baz¹ wiedzy jest systemem typu MISO (ang. Multiple Input Single Output) o wielu wejciach i jednym wyjciu. Jego strukturê oraz po-wi¹zania z otoczeniem decyzyjnym przedstawia rysunek 2. Omawiany system wnioskuj¹cy sk³ada siê z nastêpuj¹cych czêci (por. [12, 15, 17, 18, 20, 25]):
bazy wiedzy (ang. knowledge base), która zawiera wie-dzê dziedzinow¹ istotn¹ dla danego problemu,
bloku rozmywania (ang. fuzzification), który zamienia dane wejciowe z dziedziny ilociowej na wielkoci ja-kociowe reprezentowane przez zbiory rozmyte na pod-stawie okrelaj¹cych je stopni przynale¿noci zapisa-nych w bazie wiedzy,
bloku wnioskowania (ang. inference), który korzysta z bazy wiedzy oraz zaimplementowanych metod agre-gacji i koñcowego wnioskowania w celu rozwi¹zania specjalistycznych problemów,
bloku wyostrzania (ang. defuzzification), który na pod-stawie wynikowych stopni przynale¿noci, oblicza ilo-ciow¹ (ostr¹) wartoæ na wyjciu systemu.
Podstaw¹ bazy wiedzy probabilistyczno-rozmytego modelu s¹ dwa komponenty: baza danych (ang. data base) oraz baza probabilistyczno-rozmytych regu³ (ang. rule base) (por.[9]). Baza danych zawiera informacje definiowane przez eksperta z danej dziedziny zastosowania, do których nale¿¹ wartoci lin-gwistyczne {An
m, Bj/m , j=1,...J, n=1,...,N, m=1,...,M} (por. (4))
zmiennych rozwa¿anych w bazie regu³ oraz definicje zbiorów rozmytych uto¿samianych z tymi wartociami. Natomiast baza probabilistyczno-rozmytych regu³, jak wskazuje sama nazwa, zawiera zbiór regu³ lingwistycznych w postaci (4), któ-re s¹ tworzone na podstawie zmodyfikowanego algorytmu ge-neruj¹cego rozmyte regu³y asocjacji. Algorytm pozwala na dopasowanie modelu do danych pomiarowych. Charaktery-styczna postaæ regu³, ukazuj¹ca empiryczny rozk³ad prawdo-podobieñstwa zdarzeñ rozmytych, pozwala na ³atw¹ interpre-tacjê zawartej w modelu wiedzy oraz umo¿liwia dodatkow¹ analizê rozwa¿anego zagadnienia.
Szczegó³y poszczególnych bloków systemu zostan¹ opisa-ne w kolejnych podpunktach artyku³u.
2.1. Probabilistyczno-rozmyta reprezentacja wiedzy Sporód wachlarza formalizmów reprezentacji wiedzy w dzie-dzinie systemów wnioskuj¹cych, najbli¿sz¹ metod¹ zapisu wiedzy stosowan¹ przez cz³owieka jest regu³owa reprezen-tacja wiedzy typu JE¯ELI-TO. Zaczerpniêta z dziedziny logiki matematycznej, ogólna postaæ regu³owej reprezentacji wiedzy, zwanej te¿ regu³ami wnioskowania lub regu³ami de-cyzji, sk³ada siê z czêci warunkowej pr, zwanej przes³ank¹ b¹d poprzednikiem regu³y (ang. antecedent) oraz czêci de-cyzyjnej qr, zwanej konkluzj¹ b¹d nastêpnikiem regu³y (ang. consequent). Zatem ogólna postaæ regu³y ma formê:
JE¯ELI pr TO qr (2)
gdzie s³owa JE¯ELI (ang. IF), TO (ang. THEN) stanowi¹ s³owa kluczowe poprzedzaj¹ce odpowiednio przes³ankê i konkluzjê regu³y.
Szczegó³owa postaæ bazy regu³ kszta³tuje siê w zale¿noci od zastosowanego modelu. Prostota zapisu oraz ³atwoæ in-terpretacji i wnioskowania na podstawie regu³ typu JE¯E-LI-TO wp³ynê³y na ogromn¹ popularnoæ ich zastosowania w strukturach modeli rozmytych, jak i neuronowo-rozmy-tych. Zalet¹ jest tak¿e mo¿liwoæ opracowania modeli na bazie znacznie mniejszej iloci informacji o systemie [18] w porównaniu z modelami matematycznymi. Chêæ uzyska-nia coraz to wiêkszej dok³adnoci odwzorowauzyska-nia ró¿norod-nych systemów rzeczywistych, z ró¿nym stopniem dostêp-noci informacji i ich form, spowodowa³o intensywny roz-wój struktur modeli [15].
Do najpopularniejszych modeli rozmytych nale¿y model typu Mamdaniego, który pozwala na odwzorowanie wejcia modelu (x) na wyjcie (y) poprzez zbiór rozmytych regu³ wa-runkowych (ang. fuzzy conditional rules) w postaci:
JE¯ELI x = Ai TO y = Bj (3) gdzie:
x stanowi zmienn¹ wejciow¹ modelu, y zmienn¹ wyjciow¹,
Ai,Bj wartoci zmiennych lingwistycznych, które s¹ uto¿-samiane ze zbiorami rozmytymi, odpowiednio dla wejcia i dla wyjcia modelu.
Omawiany w artykule system wnioskuj¹cy z probabili-styczno-rozmyt¹ baz¹ wiedzy jest oparty na modelu, który jest rozszerzeniem modelu typu Mamdaniego. W litera-turze spotykany jest pod nazw¹ rozmyty model b¹d rozmy-ta reprezenrozmy-tacja wiedzy z miarami prawdopodobieñstwa zbiorów rozmytych [23]. Charakterystyczn¹ cech¹ bazy wiedzy omawianego modelu dla systemu typu MISO jest reprezentacja wiedzy w postaci regu³ plikowych, stanowi¹-cych zbiór J regu³ elementarnych, w formie [21]:
gdzie:
N liczba zmiennych wejciowych modelu, M liczba regu³ plikowych,
x1, , xN zmienne wejciowe modelu, xnÎXnÌR, n=1,..., N,
y zmienna wyjciowa modelu, yÎYÌR, An
m m-ta wartoæ lingwistyczna n-tej zmiennej
wejcio-wej, m=1, ,M, n=1,..., N,
Bj/m wartoæ lingwistyczna zmiennej wyjciowej w j-tej regule elementarnej m-tej regu³y plikowej, m=1, ,M, j=1, ,J.
Wagi wm, wj/m stanowi¹ miary prawdopodobieñstw zbiorów rozmytych. Waga m-tej regu³y plikowej wm reprezentuje ³¹czne prawdopodobieñstwo zdarzeñ rozmytych Am=A1
m´...´ANm w przes³ance regu³y plikowej:
(5) gdzie x=[x1, x1,..., xN].
Natomiast waga elementarnej regu³y wj/m reprezentuje
wa-runkowe prawdopodobieñstwo zdarzeñ rozmytych, które na podstawie twierdzenia Bayesa obliczane jest jako:
(6)
W ujêciu teorii zbiorów rozmytych wg Zadeha, prawdopo-dobieñstwo zdarzenia rozmytego A obliczane jest jako:
(7) dla dyskretnej przestrzeni rozwa¿añ À={x1,x1,...,xN}, gdzie
p(xi)Î[0,1] stanowi prawdopodobieñstwo (nierozmyte) zdarzenia elementarnego xi, przy czym Si=1,...,n p(xi)=1.
Wed³ug [23] wagi obliczane s¹ dla wartoci lingwi-stycznych An
m, Bj/m okrelonych na niepustych
przestrze-niach Xn i Y zdyskretyzowanych do roz³¹cznych prze-dzia³ów wartoci zmiennych, oznaczonych odpowiednio an
k i bk:
(8) z zachowaniem zasady podzia³u do jednoci. Przyk³ad defi-nicji zbiorów rozmytych dla roz³¹cznych przedzia³ów zmiennych przedstawia rysunek 3.
Korzystaj¹c z definicji przeciêcia zbiorów rozmytych (opartej na operatorze t-normy) oraz w³asnoci (5-6), waga wm definiowana jest jako:
natomiast waga wj/m jako:
gdzie p(a1
k,...,aNk,bk) (p(a1k,...,aNk)) stanowi
prawdopodo-bieñstwo zajcia jednoczenie zdarzeñ nierozmytych a1
k,...,aNk,bk (a1k,...,aNk). Przyk³ad operatorów t-normy, jakie
s¹ mo¿liwe do zastosowania przy tworzeniu regu³, przed-stawiono w tabeli 1.
2.2. Metody pozyskiwania rozmytej bazy wiedzy Regu³y JE¯ELI-TO, stanowi¹ce podstawê bazy wiedzy sys-temu rozmytego, mog¹ byæ definiowane na dwa sposoby: - jako regu³y logiczne, stanowi¹ce subiektywne definicje
tworzone przez cz³owieka na podstawie jego dowiad-czeñ i wiedzy o badanym zjawisku,
- jako regu³y fizyczne, stanowi¹ce obiektywne modele wiedzy, zdefi-niowane na podstawie obserwacji i badañ naturalnych zachowañ ana-lizowanego procesu (obiektu) oraz zachodz¹cych w nim prawid³owo-ciach,
W przypadku modelowania rozmytego, pocz¹tkowo mielimy do czynienia z regu³ami logicznymi, jednak¿e w miarê rozwiniêcia dziedziny maszynowego uczenia zaczêto stosowaæ hybrydê omówionych regu³, gdzie pocz¹tkowe za³o¿enia dotycz¹ce zbiorów rozmy-tych, a nawet regu³, s¹ definiowane na zasadzie przekonañ eksperta, natomiast pozosta³e parametry zostaj¹ dopasowa-ne do danych pomiarowych. Celem me-tod automatycznego pozyskiwania baz wiedzy jest uzyskanie jak najmniejsze-go zbioru rozmytych regu³ JE¯ELI-TO, który umo¿liwia jak najdok³adniejsze odwzorowanie modelowanego obiektu czy zjawiska.
Do metod pozyskiwania baz wiedzy dla rozmytych systemów typu Mam-daniego mo¿na zaliczyæ [15]: - metodê Wanga-Mendela,
- metodê Nozaki-Ishibuchi-Tanaki, - metodê Sugeno-Yasukawy, - metodê szablonowego
modelowa-nia systemów rozmytych [25]. Metody Wanga-Mendela oraz szablo-nowego modelowania systemów roz-mytych pozwalaj¹ na wydobywanie przes³anek niezale¿nie od wydobywania konkluzji regu³. Metoda Nozaki-Ishibuchi-Tanaki wydobywa przes³anki regu³, a nastêpnie konkluzje, natomiast metoda Sugeno-Yasukawy odwrotnie najpierw konkluzje, do-piero póniej przes³anki.
W celu pozyskiwania baz wiedzy do systemów rozmytych zaczêto równie¿ wykorzystywaæ metody wchodz¹ce w sk³ad obszaru zwanego data mining (zwanym inaczej eksploracj¹ da-nych).
Data mining, ja-ko g³ówny etap procesu odkrywania wiedzy (ang. knowledge discovery) [7], zajmuje siê nietrywialnymi algorytmami wyszukiwa-nia ukrytych, dot¹d nieznanych i potencjalnie potrzeb-nych informacji w dapotrzeb-nych [8] oraz zapisywania ich w po-staci wzorców i modeli. Niektóre z metod data mining iden-tyfikuj¹ regiony w przestrzeni zmiennych systemu, które póniej tworz¹ zdarzenia rozmyte w regu³ach. Mo¿e byæ to dokonane poprzez szukanie klastrów z u¿yciem algorytmów klasteringu czy te¿ identyfikacjê za pomoc¹ tzw. covering (zwanego równie¿ separate and conquer) algorytmu. Inne metody, np. rozmyte regu³y asocjacji, bazuj¹ na sta³ym roz-mytym podziale dla ka¿dego atrybutu (ang. fuzzy grid),
(9)
(10) Rys. 3. Przyk³ad definicji zbiorów rozmytych dla roz³¹cznych
a ka¿dy element siatki jest rozwa¿any jako potencjalny sk³adnik regu³y. W pierwszym podejciu ka¿da zidentyfi-kowana regu³a posiada w³asne zbiory rozmyte [24]. Dlate-go te¿, z punktu widzenia interpretacji regu³, drugie podej-cie jest korzystniejsze [11].
2.2.1. Regu³y asocjacji jako sposób na pozyskiwanie wiedzy modelu rozmytego
Niezale¿nie od metody automatycznego pozyskiwania wie-dzy, regu³y modelu rozmytego uzyskuje siê na podstawie ich optymalnego dopasowania do danych dowiadczal-nych. W tym sensie, generowanie regu³ mo¿na rozumieæ jako wyszukiwanie regu³ o du¿ej czêstoci wystêpowania, gdzie parametr czêstoci wystêpowania wp³ywa na opti-mum dopasowania regu³. W takim przypadku, regu³y w po-staci (4) mog¹ byæ analizowane jako wspó³wystêpowanie rozmytych wartoci zmiennych w kolekcjach danych do-wiadczalnych, co za stanowi sens rozmytych regu³ aso-cjacji (ang. fuzzy association rules).
Zagadnienie regu³ asocjacji zosta³o po raz pierwszy u¿yte w pracy [1]. Obecnie jest jedn¹ z czêciej wykorzystywa-nych metod data mining. W ujêciu formalnym regu³y aso-cjacji maj¹ postaæ implikacji:
(11) gdzie X i Y s¹ roz³¹cznymi zbiorami zmiennych (atrybutów) w ujêciu klasycznym zbiorów, nazwanych czêsto: X zbio-rem wartoci warunkuj¹cych, Y zbiozbio-rem wartoci warun-kowanych.
Bior¹c pod uwagê regu³y asocjacji w wersji rozmytej, otrzymujemy (por. [14]):
(12) gdzie A1,An s¹ skrótowym zapisem: zmienna zbiór
roz-myty w poprzedniku regu³y (np. An @x jest An, gdzie x
stanowi zmienn¹, An zbiór rozmyty), An+1,Am parami
zmienna zbiór rozmyty nastêpnika regu³y.
Ka¿da regu³a asocjacji jest zwi¹zana z dwiema miarami statystycznymi okrelaj¹cymi wa¿noæ i si³ê regu³y: sup-port (sup%) wsparcie, prawdopodobieñstwo jednocze-snego wystêpowania zbiorów w poprzedniku i nastêpniku regu³y oraz confidence (conf %) ufnoæ, zwane równie¿
wiarygodnoci¹, bêd¹ce prawdopodobieñstwem warunkowym (P(Y|X), P(An+1Ç...ÇAm| A1Ç...ÇAn)).
Problem odkrywania rozmytych regu³ asocjacji po-lega na znalezieniu w danej bazie danych wszyst-kich rozmytych regu³ asocjacji, których wsparcie i ufnoæ s¹ wy¿sze od zdefiniowanych przez u¿yt-kownika wartoci minimalnego wsparcia i mini-malnej ufnoci.
Pierwsze zastosowanie regu³ asocjacji mia³o miejsce w analizie koszyka zakupów (ang. basket analysis). Jednak¿e bior¹c pod uwagê, i¿ w regu³ach mog¹ wy-stêpowaæ zmienne pochodz¹ce z ró¿nych dziedzin wartoci o wartociach wyra¿onych w jêzyku natu-ralnym, wachlarz zastosowañ metody poszerza siê znacz¹co w p³aszczynie podejmowania decyzji, planowania, sterowania, prognozowania itp. Publi-kacja pokazuje równie¿, ¿e rozmyte regu³y asocjacji mog¹ byæ wykorzystywane jako metoda pozyskiwa-nia wiedzy do rozmytych systemów wnioskuj¹cych. 2.2.2. Algorytmy pozyskiwania wiedzy na bazie
rozmy-tych regu³ asocjacji
Za podstawowy algorytm odkrywania regu³ asocjacji uzna-je siê iteracyjny algorytm Apriori [1]. Algorytm ten docze-ka³ siê wielu modyfikacji, które zmierzaj¹ do poprawienia jego efektywnoci (np. AprioriTid, AprioriHybrid). W lite-raturze mo¿na znaleæ równie¿ inne algorytmy tj.: SETM, FreeSpan, Eclat, Partition. Efektywnym pod wzglêdem z³o-¿onoci obliczeñ jest algorytm FP-Growth [han00], jednak-¿e pozwala on na generowanie regu³ asocjacji jedynie w wersji nierozmytej (11). Na odkrycie rozmytych regu³ asocjacji (12) pozwalaj¹ algorytmy opisane m.in. w [5, 10, 14]. Po³¹czenie eksploracji danych metodami rozmytych regu³ asocjacji z wykorzystaniem algorytmów genetycz-nych mo¿na znaleæ m.in. w [2].
Artyku³ przedstawia w³asn¹ wersjê algorytmu, utworzone-go na za³o¿eniach alutworzone-gorytmu Apriori, w celu wykorzystania go do generowania bazy wiedzy z probabilistyczno-rozmy-tymi regu³ami dla systemu o wielu wejciach i jednym wyj-ciu. Za³o¿eniami proponowanego algorytmu jest predefi-niowana baza danych oraz wartoci progowe minimalnego wsparcia (min w). Notacja u¿yta do przedstawienia algoryt-mu jest nastêpuj¹ca (por.[24]):
I liczba pomiarów u¿ytych do identyfikacji modelu, N+1 ca³kowita liczba zmiennych (N zmiennych wejcio-wych, jedna zmienna wyjciowa),
K liczba roz³¹cznych przedzia³ów o równej szerokoci w przestrzeniach zmiennych,
xn zmienne wejciowe modelu, xnÎXnÌR, n=1,...,N, y zmienna wyjciowa modelu, yÎYÌR,
|An| (|B|) liczba wartoci lingwistycznych dla n-tej zmien-nej wejciowej (zmienzmien-nej wyjciowej),
An
j j-ta wartoæ lingwistyczna n-tej zmiennej wejciowej,
j=1, ,|An|, n=1,...,N,
Bj j-ta wartoæ lingwistyczna zmiennej wyjciowej, j=1, ,|B|,
a
n=(a1n,...,akn,...,aKn) roz³¹czne przedzia³y wartoci n-tej
zmiennej wejciowej xn, n=1,...N,
b=(b1,...,bk,...,bK) roz³¹czne przedzia³y wartoci zmiennej
wyjciowej y, Tab. 1. Przyk³ad operatorów t-normy [18]
w obliczona wartoæ wsparcia dla kandydatów w zbiorze, min w za³o¿ona przez eksperta, minimalna wartoæ wsparcia, Cr zbiór kandydatów sk³adaj¹cy siê ze zbiorów wartoci lingwistycznych dla r (1 £ r £ N+1) zmiennych systemu, Fr zestawienie zbiorów czêstych sk³adaj¹cych siê ze zbiorów wartoci lingwistycznych dla r (1 £ r £ N+1) zmiennych systemu, D dane empiryczne dotycz¹ce badanego systemu, w termi-nologii data mining czêsto okrelane jako dane transakcyjne, Di i-ty zbiór wartoci empirycznych zmiennych modelu
{xi
1,..., xiN, yi}, i=1,...I.
Za zbiór czêsty uwa¿a siê zbiór, którego prawdopodobieñ-stwo wystêpowania jest wiêksze od wartoci za³o¿onego mi-nimalnego wsparcia min w.
Algorytm do generowania regu³ dla systemu wnioskuj¹cego z probabilistyczno-rozmyt¹ baz¹ wiedzy jest przedstawiony na rysunku 4.
Dokonano próby zaadoptowania algorytmu FP-Growth do wersji, która pozwoli bezporednio wyszukiwaæ rozmyte re-gu³y asocjacji. Jednak¿e ta wersja algorytmu okaza³a siê bar-dziej z³o¿ona obliczeniowo w porównaniu ze zmodyfikowa-nym algorytmem Apriori. Czas generowania regu³ tego algoryt-mu jest d³u¿szy, mimo ¿e otrzyalgoryt-mujemy te same wyniki (rys. 5). 2.3. Wnioskowanie w oparciu o zbudowany model Mechanizm wnioskowania rozmytego modelu o wielu wej-ciach i jednym wyjciu oblicza na podstawie ostrych war-toci danych wejciowych wynikow¹ funkcjê przynale¿no-ci, a w konsekwencji ostr¹ wartoæ wyjcia modelu. Dla systemu z baz¹ regu³ w postaci (4) mo¿liwe s¹ dwa sposoby odnajdywania ostrych wyników y* [22]. Jeden ze sposo-bów wnioskowania dla przyk³adowej regu³y plikowej za-wiera rysunek 6. Przedstawione wnioskowanie wykorzy-stuje nastêpuj¹ce parametry: minimum jako operator t-nor-my (OperAND), iloczyn logiczny jako operatora implikacji rozmytej (OperImp) oraz metodê rodka ciê¿koci COA jako metodê defuzyfikacji (MethDefuzz).
3. Przyk³ad zastosowania omawianego systemu do pre-dykcji prêdkoci wiatru w elektrowniach wiatrowych Energia wiatru stanowi alternatywne, odnawialne ród³o energii. Dziêki turbinom wiatrowym istnieje mo¿liwoæ przekszta³cenia energii wiatrowej w energiê elektryczn¹. Zasoby wiatru na wiecie s¹ olbrzymie. Szacuje siê, ¿e iloæ energii wiatrowej, mo¿liwej do wykorzystania z tech-nologicznego punktu widzenia, równe jest oko³o 53 tys. TWh/rok tj. czterokrotnie wiêcej ni¿ wynosi globalne roczne zapotrzebowanie na energiê. Nie jest mo¿liwe wy-korzystanie ca³ego potencja³u wiatru, ale skutecznie mo¿e-my wykorzystaæ wiatr o prêdkoci od 3-4 do 25-30 m/s [6]. Wiatr stanowi ruch mas powietrza powstaj¹cy w wyniku nierównomiernego rozk³adu cinienia, spowodowanego nierównomiernym ogrzewaniem Ziemi przez promienio-wanie s³oneczne. Ciep³e, ogrzane powietrze, jako l¿ejsze, unosi siê do góry, a w jego miejsce przechodz¹ ch³odniejsze masy, tworz¹c cyrkulacjê powietrza. Wa¿nymi parametrami wiatru wykorzystywanymi podczas sterowania w elektrowni wiatrowej jest jego prêdkoæ i kierunek. Zale¿noæ wiatru od warunków ukszta³towania powierzchni Ziemi powoduje jego lokalne zawirowania zmiany kierunku i si³y wiatru.
Wieloletnie badania potwierdzaj¹ te¿ zmiennoæ tych para-metrów w czasie, zarówno na przestrzeni lat (zmiennoæ wieloletnia), na przestrzeni miesiêcy w roku (zmiennoæ roczna zwi¹zana z porami roku), jak i w okresie dobowym oraz minutowym (sekundowym), gdzie jest to zmiennoæ nieprzewidywalna o charakterze losowym.
Zmiennoæ parametrów wiatru, bêd¹cego ród³em energii, mo¿e zatem stanowiæ zak³ócenie dla procesu produkcji energii elektrycznej [16]. Dlatego te¿ z punku widzenia za-rz¹dzania energetyk¹ wiatrow¹, niezmiernie wa¿ne jest ujarzmienie wiatru poprzez jego identyfikacjê, poznanie jego parametrów z wyprzedzeniem czasowym, tak aby móc odpowiednio sterowaæ parametrami elektrowni. Ma to zna-czenie podczas typowej pracy mechanizmu ustawiania ³opat i kierunkowania elektrowni oraz w sytuacjach awa-ryjnych, aby móc przewidzieæ nag³e, huraganowe podmu-chy wiatru i z wyprzedzeniem zminimalizowaæ niekorzyst-ny wp³yw zak³óceñ. Prawid³owe oszacowanie zasobów energetycznych wiatru ma tak¿e decyduj¹ce znaczenie dla procesu lokalizacji elektrowni wiatrowej, planowania pro-dukcji, okrelania kosztów oraz szacowania op³acalnoci inwestycji tego typu. Moc elektrowni wiatrowej jest wprost proporcjonalna do powierzchni ³opat wirnika poruszanych przez wiatr oraz do szecianu prêdkoci wiatru, co wynika z nastêpuj¹cej zale¿noci [16]:
(13) gdzie:
N moc elektrowni wiatrowej [W], A powierzchnia ³opatek wirnika [A], r gêstoæ powietrza [kg/m3],
V prêdkoæ wiatru [m/s].
Omawiany system wnioskuj¹cy zastosowano zatem do pre-dykcji prêdkoci wiatru. W okresie 01-01-2010 do 09-01-2010 na wysokoci wirnika wiatraka zarejestrowano 11 000 pomiarów wartoci prêdkoci wiatru, w okresie próbkowa-nia co 1 minutê. Pierwsze 7 500 pomiarów stanowi³o dane ucz¹ce, kolejne dane testuj¹ce. Predykcji prêdkoci wiatru v(t) dokonywano na podstawie trzech ostatnich pomiarów prêdkoci wiatru ozn. v(t-3), v(t-2), v(t-1). Dla ka¿dej zmiennej zdefiniowano po 7 zbiorów rozmytych (o warto-ciach lingwistycznych okrelaj¹cych wiatr jako: cichy, s³aby, ³agodny, umiarkowany, doæ silny, silny, bardzo silny) przy za³o¿eniu 30-stu roz³¹cznych prze-dzia³ów wartoci tych¿e zmiennych. Przyk³ad wartoci stopni przynale¿noci dla zmiennej v(t-3) zosta³ przedsta-wiony na rysunku 7. Stopnie przynale¿noci dla pozosta-³ych zmiennych s¹ zdefiniowane analogicznie.
Dok³adnoæ predykcji parametru wiatru badano na podsta-wie pierwiastka b³êdu redniokwadratowego RMSE, który w tym przypadku jest obliczany za pomoc¹ wzoru:
gdzie:
N liczebnoæ zbioru,
v(t) wartoæ prognozowana w chwili t, v(t) wartoæ rzeczywista w chwili t.
Rys. 5. Porównanie czasu generowania rozmytych regu³ asocjacji dla zmodyfikowanych algorytmów
Apriori i FP-Growth
Rys. 6. Przyk³ad wnioskowania w systemie z probabilistyczno-rozmyt¹ baz¹ wiedzy
Rys. 7. Przyk³ad definicji zbiorów rozmytych dla prêdkoci wiatru
Liczbê elementarnych regu³ modelu oraz wartoci b³êdów RMSE dla danych ucz¹cych, w zale¿noci od parametru minimalnego wsparcia (min w), zamieszczono na rysunku 8.
Jak mo¿na zauwa¿yæ, celowe jest ograniczenie liczby regu³ do ok. 40-stu, aby móc uprociæ z³o¿onoæ modelu, zacho-wuj¹c przy tym t¹ sam¹ dok³adnoæ odwzorowania na po-ziomie b³êdu ok. 0,75 m/sec. Dopiero po pewnej wartoci minimalnego wsparcia b³¹d predykcji znacznie wzrasta, co wiadczy o zbyt prostym modelu, który nie jest w stanie odwzorowaæ odpowiednich, przewidywanych wartoci prêdkoci wiatru v. Przy takich
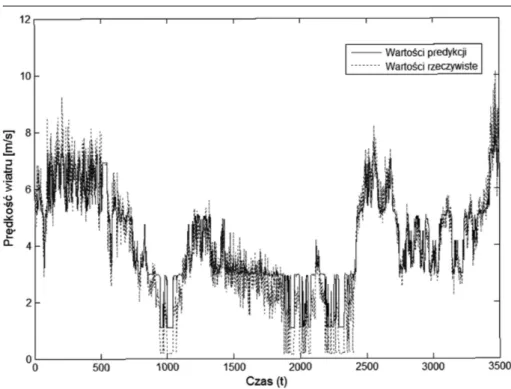
za³o-¿eniach, optymaln¹ strukturê modelu otrzymujemy przy wartoci minimal-nego wsparcia równej min w = 0,008, wówczas b³¹d redniokwadratowy dla danych ucz¹cych wynosi 0,77 m/s, dla danych testuj¹cych 0,72 m/s oraz otrzymujemy model sk³adaj¹cy siê z 42 regu³ elementarnych (24 regu³ plikowych). Porównanie predykcji z wartociami rzeczywistymi dla da-nych ucz¹cych i testuj¹cych zamiesz-czono na rysunkach 9 i 10. Zalet¹ systemu jest mo¿liwoæ podejrzenia struktury modelu, która pozwala nam oceniæ charakterystykê procesu po-przez rozk³ad prawdopodobieñstwa zajcia jednoczesnych zdarzeñ, zapi-sanych w jêzyku naturalnym dla cz³o-wieka (tab. 2).
Prêdkoæ wiatru jest parametrem trud-nym do prognozowania, st¹d te¿ nie-znaczne rozbie¿noci pomiêdzy war-toci¹ rzeczywist¹ a prognozowan¹. Wyniki na podobnym poziomie daje
predykcja z uwzglêdnieniem systemów rozmyto-wych (np. ANFIS). Jednak¿e w przypadku sieci neurono-wych utworzonego modelu nie mo¿na logicznie zinterpre-towaæ. Przedstawiona prognoza jest prognoz¹ w krótkim horyzoncie cza-sowym, st¹d ma g³ównie zastosowa-nie w sterowaniu obiektem wiatraka. Przy planowaniu produkcji energii elektrycznej i szacowaniu jej op³a-calnoci przydatna bêdzie prognoza o d³u¿szym horyzoncie czasowym. 4. Podsumowanie
Opracowanie systemu wnioskuj¹ce-go z probabilistyczno-rozmyt¹ baz¹ wiedzy otwiera nowe mo¿liwoci w modelowaniu zagadnieñ dotycz¹-cych zarz¹dzania przedsiêbiorstwem, które wymagaj¹ uwzglêdnienia nie-pewnoci w kategoriach probabili-stycznych i rozmytych jednoczenie. Zastosowanie logiki rozmytej z regu-³ow¹ baz¹ wiedzy daje mo¿liwoæ wyra¿ania informacji niepe³nej i nie-pewnej w jêzyku naturalnym, w spo-sób charakterystyczny dla cz³owieka. Zastosowanie dodatkowo prawdopo-dobieñstw zdarzeñ ujêtych w kategoriach lingwistycznych, pozwala na dostrojenie modelu na podstawie liczbowej in-formacji z danych przechowywanych w czasie dzia³alnoci przedsiêbiorstwa. Utworzony w ten sposób model staje siê ³atwy do interpretacji przez u¿ytkowników, co ma du¿e znaczenie zw³aszcza w procesie podejmowania strategicz-nych decyzji dla przedsiêbiorstwa.
Rys. 8. Liczba regu³ oraz wartoci b³êdów RMSE dla danych ucz¹cych w zale¿noci od parametru minimalnego wsparcia (min w)
Rys. 9. Porównanie wartoci predykcji i wartoci rzeczywistych prêdkoci wiatru dla danych ucz¹cych
Przedstawione w pracy rozmyte regu³y asocjacji mog¹ byæ wykorzystywane jako metoda pozyskiwania wiedzy w omawianym systemie wnioskuj¹cym. Przes³anki regu³ wydobywane s¹ wówczas niezale¿nie od ich konkluzji. Przeszukiwanie przestrzeni rozwa¿añ za pomoc¹ algoryt-mów wyszukiwania rozmytych regu³ asocjacji (w tym zmodyfikowanego algorytmu Apriori) skraca czas two-rzenia modelu i pozwala na ograniczenie jego z³o¿onoci. Dziêki zastosowaniu ró¿nych parametrów (operatorów implikacji rozmytej i operatorów t-normy) przy budowie struktury systemu, istnieje mo¿liwoæ indywidualnego dopasowania modelu do analizowanego procesu czy pro-blemu decyzyjnego.
Literatura:
[1] Agrawal R., Imielinski T., Swami A.: Mining associa-tion rules between sets of items in large databases. ACM Sigmod Intern. Conf. on Management of Data, Washington D.C., May 1993, pp. 207-216.
[2] Alcalá-Fdez J., Alcalá R., Gacto M. J., Herrera F.: Learning the membership function contexts for mining fuzzy association ru-les by using genetic algorithms. Fuzzy Sets and System, Vol. 160, 2009, pp. 905921.
[3] B³aszczyk K.: Implementation of a probabilistic-fuzzy modelling system in Matlab. X Miêdzyna-rodowe Warsztaty Doktoranckie, OWD, Warszawa 2008, str. 74-78. [4] B³aszczyk K.: Notes on Defining fuzzy sets in the created inference system with probabilistic-fuzzy knowledge base. IV rodowisko-we Warsztaty Doktorantów PO, Zeszyty Naukowe Politechniki Opolskiej. Z. 63, Elektryka, Nr 335/2010, Opole Pokrzywna 2010, str. 9-10.
[5] Chen G., Wei Q.: Fuzzy Associa-tion Rules and the Extended Mi-ning Algorithm. Information Sciences, Vol. 147, 2002, pp. 201-228.
[6] Energetycznie aspekty wiatru. Baza danych odnawialnych róde³ energii województwa podkarpac-kiego. Dostêpny w Internecie: http://www.baza-oze.pl
[7] Fayyad U., Piatetsky-Shapiro G., Smyth P.: From data mining to knowledge discovery in data-bases. AI Magazine, 1996, pp. 37-54.
[8] Frawley W., Piatetsky-Shapiro G., Matheus C.: Knowledge Disco-very in Databases: An Overview. AI Magazine, 1992, pp. 57-70. [9] Herrera F.: Genetic fuzzy systems: status, critical
con-siderations and future directions. International Jour-nal of ComputatioJour-nal Intelligence Research, Vol. 1, No. 1, 2005, pp. 59-67.
[10] Hong T.P., Kuo C.S., Chi S.C.: Trade-off between Computation Time and Number of Rules for Fuzzy Mining from Quantitative Data. International Jour-nal of Uncertainty, Fuzziness and Knowledge-Based System, Vol. 9, No. 5, 2001, pp. 587-604.
[11] Hüllermeier E.: Fuzzy methods in machine learning and data mining: status and prospects. Fuzzy Sets and System, Vol. 156, Issue 3, 2005, pp. 387-406. [12] Kacprzyk J.: Wieloetapowe sterowanie rozmyte.
Wy-dawnictwo Naukowo-Techniczne, Warszawa 2001. [13] Komiñski A. K.: Zarz¹dzanie w warunkach
niepewno-ci. Wydawnictwo Naukowe PWN, Warszawa 2005. [14] Kuok C. M., Fu A., Wong M. H.: Mining Fuzzy
Asso-ciation Rules in Database. In ACM Sigmod VI Intern. Conf. on Information and Knowledge Management, Vol. 27 Issue I, 1998, pp. 41-46.
Tab. 2. Podgl¹d rozk³adu prawdopodobieñstwa jednoczesnego zajcia wybranych zdarzeñ rozmytych, na podstawie struktury modelu predykcji prêdkoci wiatru
Rys. 10. Porównanie wartoci predykcji i rzeczywistych wartoci prêdkoci wiatru dla danych testuj¹cych
[15] £êski J.: Systemy neuronowo-rozmyte. WNT, Warsza-wa 2008.
[16] Metody oceny zasobów energetycznych wiatru. Baza danych odnawialnych róde³ energii województwa podkarpackiego. Dostêpny w Internecie: http:// www.baza-oze.pl
[17] Nowicki R. K.: Rozmyte systemy decyzyjne w zada-niach z ograniczon¹ wiedz¹. Akademicka Oficyna Wydawnicza EXIT, Warszawa 2009.
[18] Piegat A.: Modelowanie i sterowanie rozmyte. EXIT, Warszawa 2003.
[19] Piech H.: Wnioskowanie na bazie strategii rozmytych. Wydawnictwa Politechniki Czêstochowskiej, Czêsto-chowa 2005.
[20] Rutkowska D., Piliñski M., Rutkowski L.: Sieci neu-ronowe, algorytmy genetyczne i systemy rozmyte. PWN, Warszawa-£ód 1997.
[21] Walaszek-Babiszewska A.: Zbiory rozmyte jako na-rzêdzie formalizacji wiedzy ekspertów w systemach informatycznych. Zeszyty Naukowe Politechniki l¹-skiej, Organizacja i Zarz¹dzanie. Materia³y Krajowej Konferencji Naukowej Wiedza Informacja Marke-ting, Szczyrk 2004.
[22] Walaszek-Babiszewska A., Chudzicki M.: Fuzzy mo-del for the information and decission making support system for the CFM branch company. Applied Computer Science, Vol. 2, No. 1, 2006, Decision Support Engineering, Banaszak Z., Matuszek J. (Eds.), pp. 110-121.
[23] Walaszek-Babiszewska A.: Fuzzy Knowledge Repre-sentation Using Probability Measures of Fuzzy Events, [in:] Automation and Robotics, Juan Manuel Ramos Arreguin (Ed.), pp. 329-342, I-Tech Education and Publishing, Vienna 2008.
[24] Walaszek-Babiszewska A., B³aszczyk K.: A modified Apriori algorithm to generate rules for inference sys-tem with probabilistic-fuzzy knowledge base. 7th Workshop on Advanced Control and Diagnosis 19-20 November 2009, Zielona Góra, CD-ROOM.
[25] Yager R. R., Filev D. P.: Podstawy modelowania i sterowania rozmytego. WNT, Warszawa 1995. [26] Zadeh L. A.: Fuzzy sets. Inform. Contr., 1965 vol. 8,
pp. 338-353.
THE FUZZY INFERENCE SYSTEM WITH MODEL BASED ON ASSOCIATION RULES
Abstract:
In the practice of company management we deal with many tasks, that are associated with limited knowledge and un-certainty about the course of events and activities managed objects. Fuzzy IF-THEN rules are an appropriate form of describing subjective uncertainty results from lack of knowledge and objective uncertainty results from characte-ristics of different processes. On the other hand, the uncer-tainty due to randomness can be described using the theory of probability. The paper presents inference system with probabilistic-fuzzy knowledge base as a tool which can help user to analyze complete uncertainty of real problems in the company using fuzzy sets and probability. In the
mentioned system, knowledge is saved in the weighted IF-THEN fuzzy rules, where the weights constitute mar-ginal probabilities of the fuzzy events in the antecedents and conditional probabilities of the fuzzy events in the consequents.
Moreover, this paper propose using fuzzy association rules as a method of automatic knowledge base extraction in the inference system. For this purpose a modification of the Apriori algorithm was described. The algorithm extracts the most important and matching linguistic rules by as-sumption of minimum support as a minimum joint probabi-lity of the events in the rules. If minimum support equals zero, then the rules present total probabilistic distribution of the fuzzy events, otherwise the rules present probabili-stic distribution, which is the best matching to a variables universe. In the methodology of system creation, the uni-verse of quantitative variables is discretized on disjoint in-tervals of variable values and the fuzzy sets are defined by grades of membership of the disjoint intervals to fuzzy sets. This approach allows vectorize the calculation.
A numerical example is analyzed by using a wind speed prediction process. Parameter of wind speed characterized by high variability of random character. However, the cor-rect estimation of wind speed, as a energy resources, is ne-cessary for control working of wind turbine. It is also im-portant for the localization process of wind turbines, pro-duction planning and estimating cost-effectiveness of such investments.
Dr hab. in¿. Anna WALASZEK-BABISZEWSKA, prof. PO
Katedra Automatyki i Systemów Informatycznych Instytut Automatyki i Informatyki
Wydzia³ Elektrotechniki, Automatyki i Informatyki Politechnika Opolska
ul. K. Sosnkowskiego 31 45-272 Opole
a.walaszek-babiszewska@po.opole.pl Mgr in¿. Katarzyna RUDNIK
Katedra Zarz¹dzania i In¿ynierii Produkcji Instytut Innowacyjnoci Procesów i Produktów Wydzia³ In¿ynierii Produkcji i Logistyki ul. Ozimska 75
45-370 Opole k.rudnik@po.opole.pl
![Tab. 1. Przyk³ad operatorów t-normy [18]](https://thumb-eu.123doks.com/thumbv2/9liborg/3039110.6197/5.892.89.509.92.371/tab-przyk-ad-operatorów-t-normy.webp)