1. Wprowadzenie
Wed³ug P. G. Shapiro, pioniera w zakresie odkrywania wie-dzy z baz danych, odkrywanie wiewie-dzy jest nietrywialnym procesem uzyskiwania nowej dla u¿ytkownika wiedzy z ju¿ istniej¹cych w przedsiêbiorstwie baz danych, a wiêc takiej, która ju¿ siê w bazach danych znajdowa³a (wiedza jawna), ale uprzednio nie by³a znana, uwiadomiona czy dostrze¿ona [24]. Mog¹ to byæ przyk³adowo wczeniej nie-dostrze¿one zale¿noci, wzorce czy relacje. Bazy danych s¹ zazwyczaj bardzo du¿e, rzêdu gigabajtów czy wiêksze. Wymaga to u¿ycia specjalistycznych narzêdzi, pozwalaj¹-cych szybko wykryæ z³o¿one zwi¹zki pomiêdzy danymi. Wiedza to co wiêcej ni¿ informacja, to struktura, a wiêc specyficzne korelacje, prawid³owoci statystyczne lub inne zale¿noci, które daj¹ siê wypowiedzieæ w jêzyku matema-tyki lub w dowolnym jêzyku naturalnym. Nie³atwo jest do nich dotrzeæ, gdy¿ niekiedy nie podejrzewa siê nawet ich istnienia. Mog¹ one mieæ realn¹ wartoæ liczon¹ w milio-nach z³otych, na przyk³ad, jeli dotycz¹ wa¿nych dla jakie-go sektora zachowañ rynkowych. Ich uchwycenie mo¿e oznaczaæ umiejêtnoæ przewidzenia przysz³oci, a tym sa-mym uzyskanie znacz¹cej przewagi nad konkurencj¹. Za-zwyczaj ka¿da organizacja gromadzi na dyskach swoich komputerów dane, które w zale¿noci od podejcia, mog¹ mieæ albo wartoæ czysto historyczn¹, albo te¿ pos³u¿yæ do ciekawych analiz, na przyk³ad marketingowych, których koszt mo¿e ulec obni¿eniu o bardzo istotny sk³adnik - na-k³ady na samo zebranie danych.
Ekstrahuj¹c informacjê z baz danych, wiemy dok³adnie czego szukamy. Tworzenie z³o¿onych, przekrojowych ra-portów mo¿e byæ nawet bardzo skomplikowane technicz-nie, lecz zawsze jest procedur¹ dobrze okrelon¹ - raport stanowi odpowied na precyzyjnie zadane pytanie, w ro-dzaju poka¿ wszystkich klientów, którzy w ubieg³ym mie-si¹cu zamówili towary na ³¹czn¹ sumê ponad 10 tysiêcy z³otych i zalegaj¹ z p³atnoci¹. Istota eksploracji danych polega natomiast na tym, ¿e nie
potrafi-my zadaæ konkretnego pytania. Interesu-je nas tylko, czy w naszej bazie s¹ jakie prawid³owoci. Miejsce pozyskiwania wiedzy w procesie podejmowania decy-zji przedstawia rysunek 1.
Analizy data mining s¹ pomocne w trans-formacji surowych danych, poprzez kolejne etapy abstrakcji a¿ do wiedzy, która umo¿liwia podejmowanie decyzji. W aplikacjach operacyjnych wykorzy-stuje siê dane (zbiór faktów i/lub zda-rzeñ). Wykorzystuj¹c hurtowniê danych, generowane s¹ informacje, które pozwa-laj¹ na wyci¹ganie istotnych wniosków. Wnioski te, uwzglêdnione przez decy-denta podczas podejmowania przez
nie-go decyzji, mog¹ przyczyniæ siê do podjêcia lepszej decy-zji, ni¿ gdyby decydent ich nie zna³.
Aby odkrywanie wiedzy z baz danych by³o mo¿liwe, musz¹ byæ spe³nione warunki:
w organizacji ma miejsce masowe gromadzenie danych pamiêci (gromadzone dane pojawiaj¹ siê w aplikacjach na przestrzeni czasu),
organizacja posiada wysoko-wydajne maszyny wielo-procesorowe (gdy¿ zazwyczaj wykonuje siê obliczenia dla du¿ej grupy rekordów, czêsto dla wszystkich rekor-dów ze zbiorów),
w organizacji znajduj¹ siê pracownicy odpowiednio wy-kwalifikowani, umiej¹cy obs³u¿yæ data mining.
Odkrywanie wiedzy z baz danych jest procesem cyklicznym. Nie koñczy siê w momencie wdro¿enia rozwi¹zania. To, cze-go nauczymy siê w trakcie procesu i na podstawie wdro¿one-go rozwi¹zania, mo¿e przynieæ nowe, czêsto bardziej kon-kretne pytania biznesowe. Zebrane dowiadczenia przynios¹ korzyci przy kolejnych projektach pozyskiwania wiedzy. Najw³aciwsze, szczególnie z punktu widzenia z³o¿onoci, zadania, jakie stawia przed sob¹ odkrywanie wiedzy z baz danych, jest przedstawienie go w postaci procesu, który porz¹dkuje podstawowe grupy czynnoci (por. [6]). Po-zwala równie¿ na zakrelenie ram obejmuj¹cych ca³o-kszta³t problematyki zwi¹zanej z odkrywaniem wiedzy z baz danych.
Metody odkrywania wiedzy z baz danych wymagaj¹ wyko-nania czynnoci:
gromadzenia danych,
czyszczenia (miêdzy innymi obs³ugi b³êdnych lub bra-kuj¹cych danych),
integracji (³¹czenia danych pochodz¹cych z ró¿nych róde³),
selekcji (wybrania istotnych danych ze wzglêdu na ana-lizowany problem),
transformacji (nadania odpowiedniej reprezentacji wy-selekcjonowanym danym),
Ma³gorzata NYCZ
INTELIGENTNE METODY ODKRYWANIA WIEDZY Z BAZ DANYCH
dr¹¿enia (polegaj¹cego na wykorzystaniu inteligent-nych metod przetwarzania danych celem uzyskania miêdzy innymi regu³, schematów, zale¿noci),
weryfikacji (interpretacji wyników),
prezentacji wiedzy (zastosowanie wizualizacji i repre-zentacji wiedzy u¿ytkownikowi).
Odkrywanie wiedzy z baz danych to proces ¿mudny i czê-sto przerastaj¹cy mo¿liwoci percepcyjne cz³owieka, dlate-go automatyzacja pewnych operacji (grup czynnoci) nale-¿y do jej niepodwa¿alnych za³o¿eñ. Jednak, w jakim stop-niu proces odkrywania wiedzy mo¿e byæ niezale¿ny od u¿ytkownika, nie jest jasne. Coraz czêciej zauwa¿a siê, ¿e udzia³ cz³owieka w ka¿dym etapie procesu odkrywania wiedzy mo¿e znacznie zwiêkszyæ jego efektywnoæ. Eksploracje danych przeprowadzano od dawna; nie jest to zatem co, co by siê wi¹za³o jedynie ze sztuczn¹ inteligencj¹. Wykonywano je po to, aby uzyskaæ nowe informacje czy te¿ now¹ wiedzê z danych. Wiedzê z baz danych mo¿emy pozy-skiwaæ ró¿nymi metodami. Jedne metody odkrywania wie-dzy wywodz¹ siê z nauk biologicznych, inne ze statystyki i logiki matematycznej, jeszcze inne z nauki o jêzyku (lingwi-styka). Niektóre metody statystyczne czy matematyczne s¹ wykorzystywane w procesie odkrywania wiedzy. Przy klasy-fikacji metod odkrywania wiedzy mo¿na jako wyró¿nik braæ pod uwagê ró¿ne czynniki, jak na przyk³ad stopieñ czy
spo-sób przeprowadzania wnioskowania (indukcyjne, dedukcyj-ne czy abdukcyjdedukcyj-ne) b¹d ze wzglêdu na zawartoæ inteli-gencji. Ponadto, nale¿y zwróciæ uwagê, ¿e o ile metody sta-tystyczne eliminuj¹ przypadki skrajne (tn¹ po skrzyd³ach), co oznacza, ¿e s¹ one odrzucane, to metody inteligentne wy-wodz¹ce siê ze statystyki takie przypadki zachowuj¹, albo-wiem byæ mo¿e bêd¹ one w przysz³oci zal¹¿kiem nowej grupy. Przedstawiona poni¿ej klasyfikacja ze wzglêdu na za-wartoæ inteligencji dzieli metody odkrywania wiedzy na klasyczne, metody inteligentne oraz metody mieszane. 2. Klasyfikacja metod odkrywania wiedzy z baz danych Klasyfikacjê metod odkrywania wiedzy z baz danych mo¿-na ró¿nie przedstawiaæ, mo¿-na przyk³ad bior¹c pod uwagê po-ziom inteligencji zawartej w metodzie. I tak, mo¿na me-tody odkrywania wiedzy z baz danych podzieliæ na meme-tody statystyczne i matematyczne, metody zawieraj¹ce element inteligencji wywodz¹ce siê z matematyki i statystyki, nauk biologicznych i z nauk o jêzyku oraz metody miesza-ne, które sk³adaj¹ siê z przynajmniej dwóch metod (rys. 2). Przedmiotem naszego zainteresowania s¹ metody inteli-gentne, maj¹ce swe ród³a w ró¿nych uprzednio znanych naukach, jak statystyka i matematyka, nauki biologiczne oraz nauki o jêzyku.
3. Inteligentne metody odkrywania wiedzy
3.1. Metody odkrywania wiedzy wywodz¹ce siê ze staty-styki i matematyki
Inteligentne metody odkrywania wiedzy wywodz¹ce siê ze statystyki i matematyki to przyrostowe metody indukcyjne, dedukcyjne, abdukcyjne oraz inne, które nie mieszcz¹ siê w tych wy¿ej wymienionych, a ze wzglêdu na ich wagê trzeba o nich wspomnieæ, jak np. metoda rozmytego odkry-wania wiedzy czy inteligentna metoda temporalna. 3.1.1. Metoda przyrostowa
Poniewa¿ gospodarka egzystuje w rodowisku zmieniaj¹-cym siê w czasie, istnieje zapotrzebowanie na metody ucz¹-ce, które bior¹ pod uwagê ten fakt. Za³o¿enie to uwzglêd-niaj¹ metody zwane czêsto w literaturze algorytmami ucze-nia przyrostowego (ang. incremental learning) [8].
Koncepcja uczenia przyrostowego powsta³a w odpowiedzi na coraz bardziej z³o¿one i zmienne rodowisko dzia³ania systemów sztucznej inteligencji. Je¿eli system taki ma efektywnie rozwi¹zywaæ problemy wiata rzeczywistego, to musi byæ adaptacyjny, dopasowywaæ siê do czêstych zmian. Jednoczenie w warunkach rzeczywistych czêsto niemo¿liwe jest czekanie z podjêciem decyzji na du¿¹ iloæ obserwacji, które mog¹ te¿ w momencie uczenia byæ nie-kompletne.
Uczenie przyrostowe jest szczególnym przypadkiem pro-cesu uczenia, w którym system nie czeka przed stworze-niem pojêcia na wszystkie przypadki prezentowane w ci¹-gu ucz¹cym. Wrêcz przeciwnie po ka¿dym przypadku sys-tem stara siê dokonaæ jak najlepszego uogólnienia. Jednoczenie z ka¿dym kolejnym przypadkiem system udo-skonala nabywan¹ wiedzê. Proces uczenia ma charakter ci¹-g³y, a nabywana wiedza jest rozwijana na podstawie infor-macji, jakich dostarczaj¹ kolejne analizowane przypadki. Metodê przyrostow¹ mo¿na podzieliæ na dwie grupy. Wyda-je siê, ¿e najbardziej adekwatna Wyda-jest klasyfikacja, propono-wana m.in. przez D. Fishera [7]. Dzieli ona metody przyro-stowe stosuj¹c do nich klasyfikacjê stosowan¹ do standar-dowych metod uczenia na metody uczenia nadzorowanego i metody uczenia bez nadzoru.
Implementowanie algorytmów uczenia przyrostowego w ró¿-nych dziedzinach nie ma jeszcze zbyt d³ugiej historii. Do-tychczas, implementuj¹c algorytm przyrostowy, koncen-trowano siê bardziej na badaniu poprawnoci dzia³ania al-gorytmu i na jego osi¹gniêciach wzglêdem algorytmów tradycyjnych, ni¿ na dziedzinie zastosowañ. Dlatego spoty-kane w literaturze wyniki testów dotycz¹ najczêciej nauk medycznych, ze wzglêdu na to, ¿e dane z tej dziedziny s¹ obfite i bardzo dobrze nadaj¹ siê do testowania. Jako inne zastosowania algorytmów z uczeniem przyrostowym pro-ponowano nastêpuj¹ce:
Rozwi¹zywanie sytuacji szachowych (D.H. Fischer i J.C. Schlimmer testowali algorytm STAGGER na ci¹gu ucz¹cym Quinlana) [7].
Interaktywne pozyskiwanie wiedzy. Problemy z pozyski-waniem wiedzy od eksperta s¹ znane od dawna. H. Bare-iss i M.E. Porter zaproponowali system z uczeniem przy-rostowym, s³u¿¹cy do interaktywnego pozyskiwania wiedzy. Jest to PROTOS [1], dzia³aj¹cy w obszarze
au-diologii klinicznej. Budowana przezeñ baza wiedzy ma strukturê DAG (Directed Acyclic Graph acykliczny graf skierowany). Równie¿ J.C. Schlimmer i D.H. Fi-scher [7] zajmowali siê tym zagadnieniem, planuj¹c ta-kie rozszerzenie algorytmu COBWEB, aby budowa³ on bazy wiedzy DAG.
Pozyskiwanie wiedzy z tekstów. Opisany w pracy [12] system SYNDIKATE wykorzystuje techniki uczenia przyrostowego do dynamicznego ulepszania zbioru sza-blonów tekstowych, u¿ywanych do tworzenia tekstowych baz wiedzy na podstawie dokumentów technicznych. Systemy monitoruj¹ce. W pracy [18] zaproponowano
wykorzystanie sieci neuronowych z przyrostowymi al-gorytmami uczenia do monitorowania pracy urz¹dzeñ medycznych. Celem takiego rozwi¹zania jest wykrywa-nie oraz identyfikacja defektów w trakcie pracy syste-mu, przy zachowaniu poprzedniej wiedzy. Autor cyto-wanej pracy proponuje zastosowanie sieci ILFN (ang. Incremental Learning Fuzzy Neuron Network). Jest to sieæ wykorzystuj¹ca do reprezentacji przestrzeni wej-ciowej neurony z funkcj¹ gaussowsk¹; to samoorgani-zuj¹cy klasyfikator, mog¹cy nabywaæ now¹ wiedzê bez zapominania starej. Mo¿e on wykrywaæ nowe klasy wzorców i uaktualniaæ swoje parametry w trakcie pracy systemu monitoruj¹cego. Jest to zatem algorytm uczenia on-line bez potrzeby posiadania informacji a priori. Po-nadto, dziêki zastosowaniu logiki rozmytej sieæ ILFN mo¿e podejmowaæ decyzje rozmyte (miêkkie) lub twar-de oraz klasyfikowaæ problemy zarówno separowane, jak i nieseparowalne liniowo.
Robotyka. W pracy [25] zaprezentowano metodê przy-rostowego uczenia w czasie rzeczywistym jako szcze-gólnie u¿yteczn¹ w problematyce sterowania robotami autonomicznymi w wielowymiarowej przestrzeni wej-ciowej.
Jeli chodzi o szeroko pojête zarz¹dzanie, to w zasadzie brakuje w literaturze przyk³adów zastosowañ algorytmów uczenia przyrostowego. Wydaje siê jednak, ¿e uczenie ta-kie mo¿na by wykorzystaæ przyk³adowo w takich celach, jak uczenie systemu ekspertowego w drodze konwersacji z cz³owiekiem, generowanie diagnoz/ekspertyz, nadzoro-wanie w czasie rzeczywistym procesu produkcyjnego (sys-tem wyposa¿ony w umiejêtnoæ uczenia przyrostowego na bie¿¹co analizowa³by nap³ywaj¹ce sygna³y), badania mar-ketingowe (system ucz¹cy siê mo¿e analizowaæ nap³ywaj¹-ce, np. z biur regionalnych, sprawozdania dotycz¹ce wiel-koci sprzeda¿y, jej struktury, preferencji klientów, zacho-wañ konkurencji itp., wspomagaj¹c tym samym analizê marketingow¹ i umo¿liwiaj¹c szybkie reagowanie na zmia-ny zachowania rynku istotnego).
3.1.2. Metody indukcyjne
Odkrywanie wiedzy za pomoc¹ metod indukcyjnych mo¿e odbywaæ siê przyrostowo albo nieprzyrostowo, zale¿nie od sposobu przyswajania wiedzy w czasie. Metoda indukcyj-nego odkrywania wiedzy w sposób przyrostowy oznacza, ¿e niejako z góry s¹ opracowane sposoby przekszta³cania pozyskanej wiedzy, a w przypadku indukcyjnego odkrywa-nia wiedzy w sposób nieprzyrostowy uczenie nastêpuje tyl-ko raz i na tym tyl-koniec. Przyk³adem indukcyjnej metody
przyrostowej s¹ drzewa decyzyjne. Odkrywanie wiedzy za pomoc¹ drzew decyzyjnych polega na stopniowym podzia-le zbioru obiektów na podzbiory, a¿ do osi¹gniêcia ich jed-norodnoci ze wzglêdu na przynale¿noæ do klas. Drzewo sk³ada siê z korzenia, z którego wychodz¹ co najmniej dwie krawêdzie do wêz³ów le¿¹cych na ni¿szym poziomie. Z ka¿dym wêz³em zwi¹zane jest pytanie o wartoæ cech, które posiada obiekt i które przenosz¹ siê w dó³ odpowied-ni¹ krawêdzi¹. Wêz³y, z których ju¿ nie wychodz¹ ¿adne krawêdzie, to licie reprezentuj¹ce klasy. D¹¿ymy do tego, aby drzewo mia³o minimaln¹ liczbê wêz³ów, wówczas otrzymane regu³y bêd¹ prostsze. Wp³yw na efektywnoæ al-gorytmu tworzenia drzew decyzyjnych ma sposób podzia³u zbioru obiektów w wêz³ach drzewa (pojedynczych cech lub kombinacji liniowych), czyli miara jakoci podzia³u (miary jednorodnoci, miary zró¿nicowania) [19, s. 202-208]. Wiêkszoæ podejæ do budowy drzew decyzyjnych odnosi siê do wyników uzyskiwanych przez ID3 i jego póniej-szych wersji C4.5 i C5. Na licie opisuj¹cej systemy wyko-rzystywane do odkrywania wiedzy system C4.5 zaliczany jest do bardziej popularnych i lepszych systemów genero-wania drzew decyzyjnych [24].
J. R. Quinlan rozwin¹³ algorytm CLS (ang. Concept Lear-ning System) [13], stosuj¹c w ID3 podejcie oparte na teorii informacji. Traktuje on drzewo decyzyjne jako ród³o in-formacji, gdy¿ dla ka¿dego obiektu generuje wiadomoæ, do jakiej klasy nale¿y ten obiekt [14, s. 15]. Iloæ informacji mo¿na mierzyæ na wiele sposobów. Niemniej za najpopu-larniejsze uwa¿a siê podejcie zaproponowane przez C. Shannona, wed³ug którego informacja przenoszona przez pewien komunikat jest zwi¹zana z iloci¹ nieokrelonoci, jak¹ dany komunikat usuwa. Liczba klas, do których mog¹ byæ zaliczane obiekty, jest traktowana jako liczba mo¿li-wych komunikatów generowanych przez drzewo decyzyj-ne. Iloæ informacji zawartej w tym komunikacie mierzona jest za pomoc¹ entropii. Entropia jest to rednia iloæ infor-macji okrelonej na zbiorze prawdopodobieñstw wszyst-kich mo¿liwych realizacji pewnego zdarzenia. Gdy liczba mo¿liwych komunikatów wynosi n, iloæ informacji zawar-tej w komunikacie generowanym przez ród³o wyra¿a siê w nastêpuj¹cy sposób [23, s. 353]:
(1) gdzie:
n liczba komunikatów,
pi prawdopodobieñstwo wyst¹pienia i-tego komunikatu. Wartoæ tej miary zale¿y od prawdopodobieñstwa wyst¹-pienia ró¿nych komunikatów. Osi¹ga ona wartoæ maksy-maln¹ w przypadku, gdy prawdopodobieñstwa wyst¹pienia wszystkich komunikatów s¹ równe, a jest równa zeru tylko w takim przypadku, gdy prawdopodobieñstwo wyst¹pienia jednego z komunikatów przyjmuje wartoæ równ¹ jednoci. Na podstawie entropii Quinlan zdefiniowa³ kryterium ko-rzyci gain(X), decyduj¹ce o wyborze atrybutów do kolej-nych wêz³ów. Mierzy ono przyrost informacji, jaki uzysku-je siê przy wyborze atrybutu X do danego wêz³a. Wyliczane jest za pomoc¹ nastêpuj¹cej formu³y:
(2)
gdzie:
C zbiór ucz¹cy,
E(C) entropia zbioru C, mierzy przeciêtn¹ iloæ informa-cji potrzebnej do zidentyfikowania klasy w zbiorze C, a wylicza siê j¹ w nastêpuj¹cy sposób:
gdzie:
freq(KLASAj ,C) liczba przypadków w C nale¿¹cych do klasy j,
|C| liczba przypadków w zbiorze C.
Ex(C) oczekiwana wartoæ informacji dla poddrzewa
po-wsta³ego w wyniku podzia³u zbioru C na podzbiory odpo-wiadaj¹ce wartociom, jakie przyjmuje atrybut X:
Pierwotnie algorytm ID3 pracowa³ jedynie na atrybutach przybieraj¹cych wartoci nominalne. W wyniku kolejnych modyfikacji J. R. Quinlan w 1993r. zaproponowa³ ulepszo-ny algorytm pod nazw¹ C4.5. Jest on wersj¹ algorytmu Quinlana, poszerzon¹ o obs³ugê brakuj¹cych wartoci oraz liczb ci¹g³ych. Dodatkowo, oprócz mo¿liwoci generowa-nia drzewa decyzyjnego, algorytm ten wzbogacono o funk-cjê generowania regu³ klasyfikacyjnych. Zmodyfikowane zosta³o równie¿ kryterium wyboru atrybutów do kolejnych wêz³ów. W miejsce poprzedniego kryterium zosta³ wpro-wadzony wskanik korzyci gain ratio(X), wyliczany w na-stêpuj¹cy sposób:
(5) gdzie:
split_info(X) mierzy informacjê uzyskiwan¹ przez po-dzia³ zbioru wed³ug wartoci cechy X, a wylicza siê j¹ w nastêpuj¹cy sposób:
Rozwi¹zanie zadania decyzyjnego mo¿na uto¿samiaæ z wygenerowaniem zestawu regu³ decyzyjnych umo¿liwia-j¹cych przewidywanie klas obiektów na podstawie warto-ci atrybutów warunkowych. Zbiór regu³ decyzyjnych wy-znaczany jest na podstawie informacji dostarczanych przez skoñczony zbiór treningowy sk³adaj¹cy siê z obiektów o znanych wartociach atrybutów. Wartoci niektórych atrybutów warunkowych dla pewnych obiektów mog¹ byæ nieznane. Mówi siê wtedy o brakuj¹cych wartociach. B³¹d klasyfikacyjny w przypadku du¿ych baz danych jest szaco-wany zwykle na podstawie liczby b³êdnych sklasyfikowañ przypadków ze zbioru testowego. Istniej¹ ró¿ne algorytmy realizacji drzew decyzyjnych, jak np. Algorytm ProbRo-ugh, Algorytm C4.5, Algorytm T2, System Rosetta, Algo-rytm CN2, CART, Quest czy OC1 [21].
Z algorytmami tworz¹cymi drzewa decyzyjne zwi¹zane s¹ nastêpuj¹ce problemy: które z cech (atrybutów) nale¿y wy-gain(X) = E(C) Ex(C) (3) (4) (6) , , , . , .
braæ do podzia³u zbioru obiektów, kiedy zakoñczyæ podzia³ zbioru obiektów, w jaki sposób przydzielaæ obiekty znajdu-j¹ce siê w liciu drzewa do pewnej klasy.
3.1.3. Metody dedukcyjne
Baza danych uwa¿ana jest za bazê inteligentn¹, je¿eli wy-kazuje nastêpuj¹ce cechy: ma aktywn¹ naturê, co oznacza, ¿e nie czeka, aby otrzymaæ dane ze rodowiska, przecho-wuje regu³y i stosuje je po to, by baza danych nabra³a ak-tywnego charakteru oraz ma mo¿liwoæ przechowywania wiêzów integralnoci centralnie w samej bazie danych [3]. Za dedukcyjny system bazy danych mo¿emy uznaæ system posiadaj¹cy zdolnoci definiowania regu³ (dedukcyjnych), na podstawie których mo¿na wywnioskowaæ dodatkowe informacje, opieraj¹c siê na faktach zgromadzonych w ba-zie danych [5].
Regu³y s¹ specyfikowane za pomoc¹ jêzyka deklaratywne-go. Jêzyka, w którym specyfikuje siê co ma byæ uzyskane, a nie jak to uzyskaæ. Mechanizm dedukcyjny (maszyna wnioskuj¹ca) w systemie mo¿e dedukowaæ nowe fakty, ba-zuj¹c na interpretacji tych¿e regu³. Stosowany w dedukcyj-nej bazie danych model jest w pewnym sensie (chodzi o do-menê) zwi¹zany z modelem relacyjnym. Model danych jest zarazem cile zwi¹zany z logik¹, programowaniem logicz-nym i jêzykiem Prolog b¹d jego odmianami (np. Datalog czy Statelog).
W systemie dedukcyjnych baz danych przyjêto dwa za³o-¿enia:
za³o¿enie wiata domkniêtego, za³o¿enie negacji jako niepowodzenia.
Za³o¿enie domkniêtoci wiata mówi o tym, ¿e jedynymi prawdziwymi stwierdzeniami na temat obszaru analizy s¹ pozytywne asercje dla tego obszaru analizy wszystkie inne s¹ fa³szywe. Za³o¿enie negacji jako niepowodzenia stwierdza, ¿e jeli nie mo¿emy udowodniæ prawdziwoci formu³y Q, to powinnimy przyj¹æ, ¿e formu³a not(Q) jest prawdziwa. Za³o¿enie wiata domkniêtego nie pozwala nam jednak u¿ywaæ negatywnych faktów w celu wywnio-skowania dalszych faktów. W wiecie rzeczywistym czêsto wa¿ne jest, aby wyra¿aæ regu³y, których przes³anki zawie-raj¹ negatywn¹ informacjê.
Baza danych, która zawiera zbiór pozytywnych (tzn. nieza-negowanych) asercji, jest równowa¿na konwencjonalnej bazie danych bazie faktów. Mówimy, ¿e baza danych, która zawiera fakty i regu³y, jest dedukcyjn¹ baz¹ danych. Jest ona dedukcyjna, poniewa¿ za pomoc¹ regu³ mo¿emy z niej wyprowadziæ dane wirtualne dane nieprzechowy-wane w bazie faktów. Dedukcyjna baza danych nie jest ju¿ baz¹ danych w cis³ym tego s³owa znaczeniu, jest ona bli¿-sza pojêciu bazy wiedzy.
Dedukcyjn¹ bazê danych (DBD) definiuje siê jako bazê sk³adaj¹c¹ siê z trzech skoñczonych zbiorów. S¹ nimi zbiór faktów (F), zbiór regu³ dedukcyjnych (R) oraz zbiór wiê-zów integralnoci (I):
DBD = {F,R,I}.
Pojedynczy fakt mo¿e byæ traktowany jako atom. Mówimy, ¿e predykat, którego relacja jest jawnie deklarowana przez asercje, jest czêci¹ ekstensjonalnej bazy danych. Mówimy,
¿e predykat definiowany przez regu³y jest czêci¹ intensjo-nalnej bazy danych [3].
Regu³a dedukcyjna jest przedstawiana w postaci wyra¿enia: P ¬ L1 Ù ... Ù Ln przy n ³ 1,
gdzie: P atom,
L1 Ù ... Ù Ln literale reprezentuj¹ce warunki.
Ka¿dy z literali Li jest albo atomem pozytywnym (niezane-gowanym), albo atomem zanegowanym.
Wiêzy integralnoci s¹ domkniêtymi regu³ami pierwszego rzêdu (ang. closed first order formula), które dedukcyjna baza danych spe³nia. Wiêzi okrela siê jako negacjê wyra-¿enia:
¬ L1 Ù ... Ù Ln przy n ³ 1,
gdzie ka¿dy z Li (i = 1...n) jest atomem niezanegowanym
albo atomem zanegowanym.
Uwa¿a siê, ¿e dedukcyjny model danych ma na ogó³ wiêk-sze mo¿liwoci ni¿ relacyjny model danych. Przewagê de-dukcyjnej bazy danych nad konwencjonaln¹ relacyjn¹ baz¹ danych mo¿na wykazaæ, rozwa¿aj¹c pojêcie przetwarzania zapytañ rekurencyjnych [5].
W dedukcyjnej bazie danych wykorzystywane s¹ dwoja-kiego rodzaju specyfikacje: fakty oraz regu³y. Fakty od-zwierciedlaj¹ wiat rzeczywisty, regu³y za okrelaj¹ wirtu-alne relacje, które nie s¹ przechowywane, a które mog¹ zo-staæ utworzone na podstawie faktów przez mechanizm wnioskuj¹cy na podstawie specyfikacji regu³.
Logika mo¿e byæ zastosowana do baz danych, np. jako model danych. W ramach takiego modelu danych wyró¿niæ mo¿na struktury danych, operatory oraz regu³y integralno-ci. Wszystkie te trzy elementy s¹ reprezentowane w ten sam jednorodny sposób jako aksjomaty w jêzyku logiki. 3.1.4. Metody abdukcyjne
W metodzie abdukcyjnej CBR (ang. Case Based Reaso-ning) zachodzi wnioskowanie na podstawie przypadków, gdzie rozwi¹zanie nowego problemu nastêpuje poprzez od-wo³anie siê do rozwi¹zañ podobnych problemów w prze-sz³oci. Zasadnicza ró¿nica miêdzy CBR a alternatywnymi metodami sztucznej inteligencji polega na tym, ¿e CBR jest w stanie rozwi¹zywaæ problemy bez potrzeby odwo³ywa-nia siê do wiedzy ogólnej [10].
Funkcjonowanie CBR mo¿na opisaæ poprzez scharakteryzo-wanie czterech podstawowych elementów, którymi s¹ [16]: wyszukanie najbardziej podobnego przypadku lub
przy-padków,
adaptacja rozwi¹zania z przypadków wyszukanych, weryfikacja zaproponowanego rozwi¹zania,
zapamiêtanie rozwi¹zania, je¿eli przewiduje siê jego u¿ycie do rozwi¹zywania nowych problemów.
Rozwi¹zanie nowego problemu (przypadku) nastêpuje po-przez wyszukanie przypadków podobnych w bazie przy-padków i zaadaptowanie ich rozwi¹zañ do nowego proble-mu. Tak otrzymane rozwi¹zanie powinno byæ zweryfiko-wane poprzez odwo³anie siê do wiedzy dziedzinowej, eksperta lub odpowiednich testów. Je¿eli otrzymane roz-(7)
(8)
wi¹zanie nie ma swojego odpowiednika w bazie przypad-ków, to jest ono wraz z opisem przypadku zapamiêtywane. Cykl pracy metody wnioskowania na podstawie przypad-ków przedstawia rysunek 3.
Akwizycja wiedzy jest procesem trudnym i pracoch³on-nym. W przypadku CBR wymaga siê jedynie, aby ekspert poda³ przyk³ady rozwi¹zañ konkretnych zadañ i okreli³ ce-chy determinuj¹ce rozwi¹zanie. Metoda jest bardzo przy-datna w dziedzinach, gdzie brakuje jednoznacznych regu³ postêpowania czy okrelonej teorii problemu. Wyjanianie wygenerowanej propozycji rozwi¹zania w systemach sto-suj¹cych metodê CBR sprowadza siê do przedstawienia u¿ytkownikowi pe³nego opisu wyszukanego przypadku. Jest to z regu³y przekonywaj¹ce dla u¿ytkownika, niemniej brak tu charakterystycznego dla systemów ekspertowych objaniania drogi dojcia do rozwi¹zania. Cech¹ charak-terystyczn¹ CBR jest automatyczne rozbudowywanie bazy przypadków, dziêki czemu system jest w stanie generowaæ rozwi¹zania w sytuacji zmian w wiecie zewnêtrznym. W klasycznych systemach ekspertowych ka¿da zmiana wymaga rêcznej aktualizacji
regu³ lub wprowadzenia no-wych. Tak wiêc CBR jest w stanie korygowaæ swoje b³êdy poprzez adaptacjê no-wych, poprawnie rozwi¹za-nych przypadków. Metoda ta znajduje szerokie zastosowa-nia w wielu obszarach. Przy-k³ad praktycznego wykorzy-stania CBR mo¿na znaleæ np. w pracy [2, s. 34-43].
3.2. Inne metody odkrywania wiedzy wywodz¹ce siê z matematyki
3.2.1. Metoda rozmyta
Metody rozmytego odkrywania wie-dzy bazuj¹ na logice rozmytej (ang. fuzzy logic). Wnioskowanie rozmyte, podobnie jak teoria zbiorów rozmy-tych, w wielu przypadkach pozwala na opisywanie wiata w sposób bar-dziej odpowiadaj¹cy rzeczywistoci ni¿ logika binarna. Pozwala ono sfor-malizowaæ fakt niepewnoci i niedo-k³adnoci przes³anek oraz niepewno-ci wniosków. Implikacja mo¿e mieæ ró¿ny stopieñ spe³nienia przes³anek i wskutek tego ró¿ny stopieñ spe³nie-nia konkluzji.
Klasyczna metoda rozmytego odkry-wania wiedzy (wnioskoodkry-wania roz-mytego) sk³ada siê z trzech czêci: bloku rozmywania (fuzyfikacji), blo-ku wnioskowania (inferencji) oraz bloku wyostrzania (defuzyfikacji). Elementy metody rozmytego odkry-wania wiedzy przedstawia rysunek 4. Na wejciu systemu, w bloku rozmy-wania, pojawiaj¹ siê konkretne toci, np. dochód = 3 000 z³. Ta war-toæ podlega rozmywaniu poprzez obliczenie stopnia przynale¿noci do zbiorów stosowanych w systemie. Stopieñ zaktywizowania tych zbiorów stanowi podstawê do póniejszego wnioskowania.
W bloku wnioskowania oceniany jest stopieñ spe³nienia przes³anek ka¿dej regu³y, okrelany jest kszta³t zbiorów rozmytych poszczególnych konkluzji, a nastêpnie konklu-zje te s¹ agregowane w jeden wynikowy zbiór rozmyty. Integralnym elementem bloku wnioskowania jest baza regu³. Baza ta ma zazwyczaj postaæ zbioru przes³anek oraz okrelo-nej dla nich konkluzji. Regu³y operuj¹ okrelonymi charak-terystycznymi stanami zmiennych wejciowych zwykle kilkoma dla ka¿dej zmiennej (np. niski, redni, wysoki), na-tomiast wyjcie to jedna zmienna, opisana równie¿ kilkoma charakterystycznymi wartociami. Zawê¿enie opisu zmien-nych wejciowych i wyjciowych do kilku zbiorów w ¿ad-nym stopniu nie ogranicza ani mo¿liwych wartoci wejcia,
Rys. 4. Elementy metody rozmytego odkrywania wiedzy Rys. 3. Cykl pracy metody wnioskowania na podstawie przypadków
ani wartoci, które pojawiaj¹ siê na wyjciu wyniku wnio-skowania.
W bloku wyostrzania rozmyt¹ decyzjê nale¿y zamieniæ na jedn¹, konkretn¹ wartoæ, np. zdolnoæ kredytowa na po-ziomie 24 tys. z³. Metodê wyostrzania wybiera siê w zale¿-noci od charakteru podejmowanych decyzji, a tak¿e od postaci uzyskiwanej rozmytej konkluzji.
Metody rozmyte maj¹ kilka istotnych zalet, z których dla celów wydobywania u¿ytecznej wiedzy najwa¿niejsze s¹: regu³owe modelowanie i wnioskowanie,
zazwyczaj mniejsza liczba regu³ ni¿ w konwencjonal-nych systemach regu³owych,
mo¿liwoæ automatycznego uczenia systemu. Automatyczne uczenie jest kluczow¹ operacj¹ w procesie odkrywania wiedzy, gdy¿ w³anie na tym etapie wyszuki-wane s¹ najlepsze regu³y i okrelane s¹ parametry syste-mu wnioskuj¹cego. Odkrywanie wiedzy z danych jest re-alizowane poprzez zastosowanie odpowiednich algoryt-mów poszukuj¹cych lub ucz¹cych. Uczenie systealgoryt-mów rozmytych jest najczêciej realizowane za pomoc¹ rozmy-tych sieci neuronowych, z wykorzystaniem analizy sku-pieñ (grupowanie, klastering) oraz poprzez poszukiwania optymalnych parametrów oparte na algorytmach gene-tycznych.
3.2.2. Metoda temporalna
Mo¿na wyró¿niæ dwa podstawowe podejcia do metod wnioskowania po czasie (temporalnych): podejcie oparte na modelach (np. szeregi czasowe por. metody klasyczne) oraz podejcie oparte na jêzykach temporalnych, czyli przeznaczonych specjalnie do opisu rzeczywistoci zmiennej w czasie i wykorzystuj¹ce techniki automatycz-nego wnioskowania. Przyk³adem implementacji jest jêzyk akcji temporalnych TAL (Temporal Action Language) (por. [4 oraz 15, s. 542-546]).
Podstawowe cechy TAL to pojêcie i notacja czasu nieza-le¿na od akcji, mo¿liwoæ definiowania zale¿noci przy-czynowych w oddzieleniu od definicji akcji oraz mo¿li-woæ opisu interakcji wspó³bie¿nych. TAL sk³ada siê z dwóch poziomów, którymi s¹: jêzyk powierzchniowy, u¿ywany do opisu scenariuszy (wiêcej informacji w [4, 15]) oraz jêzyk bazowy (inaczej jêzyk logiki zdarzeñ), bê-d¹cy uporz¹dkowan¹ logik¹ predykatów I rzêdu. Warstwa jêzyka bazowego (logika zdarzeñ) zawiera m.in. predyka-ty temporalne (definicje predykatów mo¿na znaleæ np. w [15]). Warstwa jêzyka powierzchniowego sk³ada siê z wyra¿eñ temporalnych, wyra¿eñ wartociuj¹cych, wy-ra¿eñ atomicznych, stwierdzeñ narracyjnych oraz dodat-kowych makrooperatorów i skrótów. Jêzyk powierzchnio-wy nie ma formalnej semantyki, posiada natomiast for-maln¹ sk³adniê. Ca³oæ wnioskowania formalnego jest przeprowadzana po przet³umaczeniu opisu dokonanego w jêzyku powierzchniowym na opis w jêzyku bazowym. Opis (specyfikacja) scenariusza zdarzeñ w jêzyku TAL sk³ada siê z opisu typów, definicji i opisu akcji, specyfika-cji ograniczeñ dziedzinowych, specyfikaspecyfika-cji zale¿noci temporalnych [19, s. 209-210]. Przedstawiona metoda temporalna odkrywania wiedzy jest interesuj¹ca, ale jak na razie nie zdoby³a jeszcze szerokiego uznania wród u¿ytkowników.
3.3. Metody wywodz¹ce siê z nauk biologicznych Wa¿n¹ grupê metod odkrywania wiedzy tworz¹ metody wywodz¹ce siê z nauk biologicznych w tym sensie, ¿e po-wsta³y z obserwacji zachowania siê organizmów ¿ywych w przyrodzie, jak np. praca mózgu (sieci neuronowe), ewo-lucja chromosomów (algorytmy genetyczne) czy zachowa-nia siê mrówek przy wyborze cie¿ki poruszazachowa-nia siê (meto-dy mrówkowe). Najczêciej stosowane s¹ dwie pierwsze metody i to one zostan¹ poni¿ej krótko scharakteryzowane. 3.3.1. Sieci neuronowe
Sieci neuronowe mog¹ byæ stosowane do odkrywania wie-dzy z baz danych w sytuacji, gdy trudno jest sformalizowaæ regu³y dotycz¹ce danej dziedziny (np. na podstawie sesji gie³dowych mo¿emy prognozowaæ za pomoc¹ sieci spadek czy wzrost poszczególnych spó³ek).
Sztuczne neurony mo¿na traktowaæ jako elementarne pro-cesory o nastêpuj¹cych w³asnociach [17]:
Ka¿dy neuron otrzymuje wiele sygna³ów wejciowych i wyznacza na ich podstawie swoj¹ odpowied, tzn. jeden sygna³ wyjciowy.
Z ka¿dym oddzielnym wejciem neuronu zwi¹zany jest parametr zwany wag¹ (ang. weihgt). Wyra¿a on stopieñ wa¿noci informacji docieraj¹cych tym wejciem. Sygna³ wchodz¹cy okrelonym wejciem jest najpierw
przemna¿any przez wagê danego wejcia. Tak wiêc w dalszych obliczeniach uczestniczy ju¿ w formie zmo-dyfikowanej: wzmocnionej (jeli waga > 1) lub st³umio-nej (jeli 0 < waga < 1), lub nawet przeciwstawst³umio-nej w stosunku do sygna³ów z innych wejæ, gdy waga jest ujemna (tzw. wejcie hamuj¹ce).
Po przemno¿eniu przez wagi sygna³y wejciowe s¹ su-mowane, daj¹c w efekcie pewien pomocniczy sygna³ wewnêtrzny, który bywa okrelany jako ³¹czne pobudze-nie neuronu.
Do tak utworzonej sumy sygna³ów dodaje siê niekiedy pewien dodatkowy sk³adnik niezale¿ny od sygna³ów wejciowych nazywany progiem.
Suma tak przetworzonych sygna³ów mo¿e byæ traktowa-na bezporednio jako sygtraktowa-na³ wyjciowy. I w wielu sie-ciach to wystarcza. Natomiast w siesie-ciach o bogatszych mo¿liwociach sygna³ wyjciowy neuronu jest obliczany za pomoc¹ pewnej, bardzo czêsto nieliniowej, zale¿noci miêdzy ³¹cznym pobudzeniem a sygna³em wyjciowym. Zale¿noæ sygna³u wyjciowego od ³¹cznego pobudzenia,
zwana charakterystyk¹ neuronu, pozwala w ka¿dej chwili jednoznacznie okreliæ sygna³ wyjciowy neuronu. W sztucznym neuronie (rys. 5) mo¿na wydzieliæ dwa bloki, jakimi s¹ blok sumowania å oraz blok aktywacji F. Sygna³ wyjciowy otrzymuje siê poprzez przetworzenie ³¹cznego pobudzenia w bloku aktywacji. Przetwarzanie w bloku ak-tywacji mo¿e byæ zale¿nie od potrzeb opisane ró¿nymi funkcjami. Funkcja aktywacji mo¿e byæ funkcj¹ liniow¹, progow¹ lub sigmoidaln¹.
Sieci neuronowe mog¹ byæ ró¿nie klasyfikowane. Do naj-czêciej stosowanych nale¿y podzia³ na dwie klasy, jakimi s¹ sieci jednokierunkowe (ang. feedforward), w strukturze których nie ma sprzê¿eñ zwrotnych, oraz sieci Hopfielda, zawieraj¹ce sprzê¿enia zwrotne.
Topologia sieci jednokierunkowych mo¿e byæ ró¿na. Naj-³atwiej rozpatrywaæ sieci o uk³adzie warstwowym, czyli gdzie neurony pogrupowane s¹ w warstwy, a po³¹czenia wystêpuj¹ tylko miêdzy warstwami bezporednio ze sob¹ s¹siaduj¹cymi. Takie sieci s¹ najbardziej rozpowszechnio-ne. Po³¹czenia miêdzy neuronami s¹siednich warstw mog¹ byæ ró¿ne, ale czêsto stosowany jest uk³ad ka¿dy z ka¿-dym. G³ównym przes³aniem do stosowania takiego uk³adu jest nadzieja, ¿e w procesie uczenia wagi po³¹czeñ zbytecz-nych z punktu widzenia rozwi¹zywanego zadania zostan¹ ustawione na zero, co w praktyce przerwie niepotrzebne po-³¹czenia. Wród warstw sieci mo¿na wyró¿niæ warstwê wejciow¹, warstwy ukryte oraz warstwê wyjciow¹. War-stwa wejciowa ma najczêciej elementy o jednym wejciu. Jest to swego rodzaju uk³ad receptorów odbieraj¹cych sy-gna³y wejciowe i po wstêpnym ich przetworzeniu (np. normalizacji czy filtracji) przesy³aj¹cych je do elementów warstwy nastêpnej. Warstwa wyjciowa produkuje sygna³y wyjciowe z ca³ej sieci. Warstwa wejciowa jest nazywana warstw¹ zerow¹ sieci, st¹d te¿ sieæ maj¹ca tylko warstwê wejciow¹ i wyjciow¹ jest czêsto nazywana sieci¹ jedno-warstwow¹. Sieæ, która ma rozwi¹zywaæ bardziej z³o¿one zadania, powinna mieæ poza warstw¹ wejciow¹ i wyj-ciow¹ jeszcze jedn¹ lub kilka warstw ukrytych. Przyk³ad sieci neuronowej przedstawia rysunek 6.
Problem doboru liczby warstw jest wa¿ny. Jeli bêdzie za ma³o warstw ukrytych (np. sieci jednowarstwowe), to sieæ mo¿e mieæ za ma³y potencja³ i nie bêdzie w stanie wy³owiæ, uogólniæ i zapamiêtaæ cech, które s¹ jej przekazywane w trakcie procesu uczenia. Jeli sieæ bêdzie mia³a z kolei za du¿o warstw ukrytych, to istnieje niebezpieczeñstwo uczenia siê na pamiêæ. Liczba po³¹czeñ miêdzy neurona-mi pozwala na takie ustawienie wag, ¿e zapaneurona-miêtywany
jest ka¿dy element ci¹gu ucz¹cego, nie s¹ odnajdywane ¿adne ogólne cechy. Sieæ taka dzia³a bezb³êdnie dla ci¹gu ucz¹cego, ale jest bezradna wobec jakiegokolwiek elemen-tu spoza ci¹gu.
Odkrywana wiedza znajduje siê w ci¹gu ucz¹cym (zbiorze przyk³adów zebranych do procesu uczenia sieci), który sta-nowi bazê danych (np. w przypadku udzielenia kredytu wnioski kredytowe z informacjami na temat sp³acania kredytu). Mo¿liwe s¹ dwa warianty uczenia sieci: z nauczy-cielem (sieci podaje siê sygna³y wejciowe i odpowiednie oczekiwane wartoci wyjcia; zbiór przyk³adów zebranych do procesu uczenia sieci nazywa siê ci¹giem ucz¹cym) oraz sieci bez nauczyciela (sieci podaje siê szereg przyk³adów danych bez informacji na temat oczekiwanego wyjcia; sieæ sama powinna zbudowaæ sensowny algorytm dzia³a-nia, polegaj¹cy zazwyczaj na wykryciu klas wród przed-stawianych sygna³ów wejciowych).
Do typowych zadañ rozwi¹zywanych przez sieci neurono-we mo¿na zaliczyæ m.in.:
Predykcja sieæ jest wykorzystywana do tego, aby na podstawie okrelonych danych wejciowych przewidy-waæ okrelone dane wyjciowe.
Podobieñstwo sieæ zawiera pojedynczy element wyj-ciowy o aktywacji przyjmuj¹cej wartoci z pewnego przedzia³u. Wartoæ wyjcia informuje na ile podobny jest obraz podany na wejciu do obrazu urednionego po dotychczasowych prezentacjach.
Analiza czynników g³ównych sieæ posiada wyjcie wie-loelementowe, a ka¿dy z elementów wyjciowych odpo-wiada za jeden z tzw. czynników g³ównych. Stan aktyw-noci ka¿dego elementu wyjciowego jest miar¹ nasyce-nia prezentowanego obrazu danym czynnikiem g³ównym. Klasyfikacja sieæ zawiera wieloelementowe wyjcie o wartociach binarnych. Po podaniu sygna³u na wejciu uaktywnia siê jeden i tylko jeden element wyjciowy. Sy-gna³ wejciowy zostaje wiêc podporz¹dkowany okrelonej klasie reprezentowanej przez aktywny element wyjcia, Kodowanie wektor wyjciowy sieci jest zakodowan¹
wersj¹ wektora wejciowego.
Filtracja sygna³ów na wyjciu sieci pojawia siê sygna³ wejciowy oczyszczony z szumów i zak³óceñ.
Optymalizacja sieci neuronowe doskonale nadaj¹ siê do poszukiwania rozwi¹zañ optymalnych. Okrelenie wejcia i wyjcia zale¿y od konkretnej realizacji.
3.3.2. Metody ewolucyjne
Sporód wielu ró¿nych metod ewolucyjnych na szczególn¹ uwagê zas³uguj¹ metody genetyczne, w literaturze okrelane mianem algorytmów ge-netycznych (AG) (ang. GA Genetic Algori-thm), wywodz¹ce siê od mechanizmu ewolucji chromosomów dokonuj¹cego siê w naturze. Na-turalna selekcja powoduje, ¿e systemy lepiej przystosowane (a wiêc posiadaj¹ce lepsze chro-mosomy) prze¿ywaj¹ i przekazuj¹ swój genotyp potomstwu, natomiast osobniki gorzej przystoso-wane gin¹, a wraz z nimi ginie ich materia³ gene-tyczny. Jednym z obszarów potencjalnych zasto-sowañ, w których algorytmy genetyczne oferuj¹ alternatywn¹ i efektywn¹ strategiê poszukiwania Rys. 5. Budowa sztucznego neuronu
jest symboliczne uczenie siê regu³ i wzorców z baz danych. Znajduj¹ one zastosowanie zarówno w uczeniu z nadzo-rem, jak i w uczeniu bez nadzoru. Wiêkszoæ istniej¹cych systemów maszynowego uczenia odkrywa regu³y klasyfi-kacyjne na podstawie wstêpnie sklasyfikowanych przyk³a-dów (uczenie na podstawie przyk³aprzyk³a-dów (ang. CBR - Case Based Reasoning)). Systemy te maj¹ k³opoty, kiedy dane s¹ redundantne i zak³ócone.
Algorytmy genetyczne wykorzystuj¹ operacje krzy¿owa-nia i mutacji. S¹ adaptacyjnymi metodami przeszukiwakrzy¿owa-nia, których efektywnoæ przewy¿sza wiele losowych i lokal-nych algorytmów przeszukiwania (por. [9]). cis³¹ defini-cjê algorytmu genetycznego zawarto w pracy [11, s.192-193]. Wed³ug tej definicji klasycznym algorytmem gene-tycznym nazywa siê algorytm przeszukiwania przestrzeni rozwi¹zañ, chromosom za jest wektorem bêd¹cym roz-wi¹zaniem dopuszczalnym problemu P:
X = (x1,...xn) Î D(P), gdzie:
P problem optymalizacyjny z funkcj¹ celu F, D(P) zbiór rozwi¹zañ dopuszczalnych problemu P, a populacja rozwi¹zañ dopuszczalnych problemu P dla ite-racji t jest podzbiorem:
S(t) = {X1t, ...,X
mt} S(t) Ì D(P), (11)
za funkcja przystosowania U rozwi¹za-nia Xit Î S(t) jest wartoci¹ normy z
funk-cji celu dla tego rozwi¹zania: U(Xi t) = ||F(X i t)||, gdzie: U(Xit) ³ 0 X it Î S(t).
Norma || . || jest definiowana heurystycz-nie i dla najprostszego przypadku wynosi:
||F(Xit)|| = F(X it).
Operator mutacji jest przekszta³ceniem: Mk: D(P) ® D(P),
które dokonuje z prawdopodobieñstwem zadanym z góry, losowej zmiany k-tej sk³adowej rozwi¹zania Xit: Mk(Xit) = X it+1, gdzie: Xit = (x 1,....,xk,....,xn) Xit+1 = (x 1,...., xk,....,xn).
Operator krzy¿owania Kk jest to prze-kszta³cenie:
Kk : D(P) x D(P) ® D(P) x D(P),
które z prawdopodobieñstwem zadanym z góry dokonuje losowej wymiany sk³adowych rozwi¹zañ Xit i X
jt wzglêdem sk³adowej k: Kk (Xit , X jt+1), gdzie: Xit = (x 1,...,xn), Xjt = (v 1,...vn), Xit+1 = (x 1,...,xk , vk+1,...,vn), Xjt+1 = (v 1,...,vk, xk+1,...,xn).
Klasyczny algorytm genetyczny przedstawia rysunek 7. Identyfikacja grup lub klas podobnych obiektów w wielo-wymiarowej przestrzeni nie jest zagadnieniem nowym. Przez wiele lat wykorzystywano tradycyjne metody grupo-wania, jednak wykonywanie tego typu zadañ jest bardzo ograniczone ze wzglêdu na kombinatoryczny charakter tych zadañ. Algorytmy genetyczne, jako rodzina odpornych i efektywnych sposobów przeszukiwania, mog¹ byæ u¿y-teczne w rozwi¹zywaniu kombinatorycznych zagadnieñ zwi¹zanych z grupowaniem, gdzie deterministyczne algo-rytmy nie s¹ w stanie sprawdziæ wszystkich mo¿liwych rozwi¹zañ w dopuszczalnym czasie.
Rys. 7. Klasyczny algorytm genetyczny [11] (10) (12) (13) (14) (15) (16) (17)
3.4. Metody odkrywania wiedzy wywodz¹ce siê z nauki o jêzyku
3.4.1. Metody odkrywania wiedzy z tekstów
Wiedza wyra¿ana w jêzyku naturalnym zawarta w doku-mentach tekstowych jest s³abo wykorzystywana b¹d w ogóle nie jest wykorzystywana przez systemy informa-tyczne, mimo ¿e dokumenty tekstowe czêsto przybieraj¹ formê elektroniczn¹ b¹d mog¹ byæ do tej postaci prze-kszta³cone dziêki skanerom i narzêdziom typu OCR (ang. Optical Character Recognition optyczne rozpoznawanie znaków w przypadku dokumentów drukowanych) lub ICR (ang. Intelligent Character Recognition inteligentne roz-poznawanie znaków dla dokumentów pisanych odrêcznie). Niew¹tpliwie po¿¹dane jest wykorzystanie wiedzy zawar-tej w tych dokumentach w procesie odkrywania wiedzy. Dzia³ania w zakresie przetwarzania jêzyka naturalnego (ang. NLP Natural Language Processing) obejmuj¹ kilka poziomów, takich jak [10, s. 213]:
fonologia rozpoznawanie i generowanie mowy,
leksyka identyfikacja jednostek leksykal-nych (paragrafy, zdania, s³owa) i opisanie ich za pomoc¹ znaczników czêci mowy,
morfologia rozpoznawanie sufiksów, prefik-sów, fleksyjnych form s³ów, analiza z³o¿onych wyra¿eñ oraz przekszta³canie s³ów z formy, w jakich wyst¹pi³y, do postaci podstawowej, syntaktyka obejmuj¹ca zadania identyfikacji
fragmentów zdañ przez przypisywanie ról do poszczególnych s³ów z uwzglêdnieniem regu³ gramatycznych jêzyka i gramatyk¹, wed³ug której s³owa maj¹ byæ ³¹czone w analizowa-nym jêzyku; dzia³ania te s¹ pomocne przy schematach ontologicznych i wyszukiwaniu konkretnych danych,
semantyka obejmuje reprezentacjê wiedzy, usuwanie niejednoznacznoci sensu s³ów, roz-szerzenie reprezentacji wiedzy o synonimy i s³owa pokrewne,
dyskurs poziom semantyki wprowadza analizê tekstu g³ównie na poziomie zdania, poziom dyskursu bierze pod uwagê kontekst, opieraj¹c siê na dowiadczeniu i analizie ca³ej narracji,
pragmatyka wprowadza rozwi¹zania wszystkich wy-powiedzi, niejednoznacznoci, obejmuje interpretacjê intencji, intuicji, wyjaniania wyra¿eñ morfologicz-nych za pomoc¹ wiedzy zdroworozs¹dkowej, co spro-wadza siê po prostu do przekszta³cania informacji w wiedzê.
Metody odkrywania wiedzy z tekstów wspomagaj¹ takie zadania jak: grupowanie zbli¿onych tematycznie dokumen-tów, okrelanie zwi¹zków miêdzy treci¹ dokumentów a pracownikami firmy oraz przekazywanie wiedzy i jej upowszechnianie. Proces automatycznego odkrywania wiedzy z dokumentów tekstowych okrelany jest najczê-ciej mianem eksploracji dokumentów (ang. DM Docu-ment Mining). W literaturze przedmiotu terminy eksplora-cja tekstu (ang. TM Text Mining) oraz akwizyeksplora-cja wiedzy z baz tekstowych (ang. KDT Acquisition Knowledge from
Textual Databases) traktowane s¹ jako okrelenia zamienne do eksploracji dokumentów. Zatem podstawowe zadania sk³adaj¹ce siê na odkrywanie wiedzy z tekstów to identyfika-cja i pozyskiwanie róde³ wiedzy oraz wydobywanie wiedzy. W literaturze z zakresu metodologii nauk, naukoznawstwa i informacji naukowej mo¿na spotkaæ dwa ujêcia analizy tekstu:
1. Analizê logiczn¹ polegaj¹c¹ na wyró¿nianiu i ocenie elementów tekstu, które s¹ rezultatem takich operacji, jak uzasadnianie twierdzeñ, konstruowanie pojêæ, klasy-fikowanie i porz¹dkowanie. Operacje te s¹ dobrze okre-lone w logice oraz metodologii nauk, maj¹ sformu³o-wane na ich gruncie kryteria poprawnoci.
2. Analizê informacyjn¹ czyli zespó³ operacji przekszta³-caj¹cych tekst, w wyniku których otrzymuje siê infor-macje o treci tekstu.
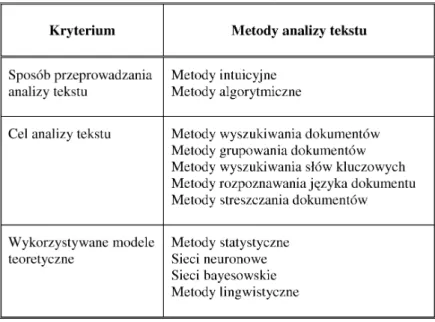
Charakterystykê metod analizy tekstu ze wzglêdu na wy-ró¿nione kryteria ich opisu przedstawia tabela 1.
Automatyzacja przetwarzania tekstów w jêzyku natural-nym prowadzona jest w dwóch kierunkach, jako:
analizy wypowiedzi (tekstu mówionego lub pisanego), syntezy wypowiedzi (tekstu mówionego lub pisanego). Zapis wiedzy w jêzyku naturalnym czy np. w HTML nie jest wystarczaj¹co dobry do automatycznego przetwarzania wiedzy. St¹d d¹¿enie do opracowania jêzyków sformalizo-wanego zapisu wiedzy oraz narzêdzi do automatycznej translacji tekstów z jêzyka naturalnego czy dokumentów hipertekstowych na jêzyk reprezentacji wiedzy. Nadzieje w tym wzglêdzie s¹ wi¹zane z ontologiami jako sformali-zowanymi modelami wiedzy [10, s. 215].
4. Porównanie efektywnoci wybranych metod odkry-wania wiedzy z baz danych
Przeprowadzony zosta³ nastêpuj¹cy eksperyment badaw-czy, maj¹cy na celu porównanie efektywnoci wybranych metod odkrywania wiedzy z bazy danych. Baz¹ danych by³a rzeczywista czeska baza danych bankowych, zaczerp-niêta z Internetu [22]. Do przeprowadzenia eksperymentu
wybrana zosta³a klasyfikacja. To samo zadanie klasyfikacji klientów banku zosta³o przeprowadzone z u¿yciem ró¿-nych narzêdzi i na podstawie otrzymaró¿-nych wyników doko-nano syntezy porównawczej. Kryterium oceny pozyskanej wiedzy w tym przypadku to procent poprawnie zaklasyfi-kowanych przypadków do grup. Na potrzeby eksperymen-tu przeprowadzonego na potrzeby niniejszej pracy zosta³y wybrane nastêpuj¹ce narzêdzia:
pakiet SPSS - narzêdzie statystyczne,
algorytm Quinlana C4.5 obs³uguj¹cy drzewa decyzyjne, pakiet Inteligent Miner obs³uguj¹cy sieci neuronowe, Oracle 9i Data Mining (regu³y asocjacyjne).
Obszar badañ ograniczy³ siê do przeprowadzenia klasyfika-cji, w której przyjêto naturalnie wystêpuj¹ce grupy klientów, a mianowicie klientów, którzy wziêli kredyty z uwzglêdnie-niem ich podzia³u na nastêpuj¹ce grupy: sp³acili zaci¹gniêty kredyt, nie sp³acili kredytu, mimo i¿ min¹³ termin, wywi¹-zuj¹ siê na bie¿¹co ze swoich zobowi¹zañ, nie wywi¹wywi¹-zuj¹ siê ze swoich zobowi¹zañ w terminie. W badaniu brano pod uwagê ró¿ne czynniki wp³ywaj¹ce byæ mo¿e na sp³acanie (lub nie) zaci¹gniêtych kredytów, jak np. region, w jakim mieszkaj¹ klienci, zamo¿noæ jego mieszkañców, iloæ po-pe³nianych przestêpstw, poziom bezrobocia oraz czy klient sp³aca³ dotychczas kredyty terminowo. Porównanie uzy-skanych wyników klasyfikacji za pomoc¹ narzêdzia staty-stycznego, sieci neuronowej, drzew decyzyjnych oraz u¿y-waj¹c Oracle Data Mining zosta³y zebrane w tabeli 2. Na te wyniki istotny wp³yw mia³a testowa baza danych. Wydaje siê, ¿e na potrzeby odkrywania wiedzy z tej bazy danych najmniej u¿yteczne by³y sieci neuronowe, ponie-wa¿ prawie co trzeci przypadek by³ b³êdnie zaklasyfikowany (29%). Z kolei metody statystyczne, drzewa decyzyjne oraz metody oraclowe wykazywa³y znacz¹co wiêksze procenty przypadków poprawnie zaklasyfikowanych do poszczegól-nych klas. Przy czym rednio 91% dok³adnoæ jest ju¿ impo-nuj¹ca (drzewa decyzyjne), za 84% uzyskane za pomoc¹ ana-lizy dyskryminacyjnej czy 89% otrzymane za pomoc¹ regu³ asocjacyjnych jest równie¿ wynikiem do zaakceptowania. Znaj¹c otrzymane wyniki eksperymentu, rodzi siê szereg pytañ odnonie mo¿liwoci uogólnienia rezultatów. Czy jest uprawnione stwierdzenie, ¿e drzewa decyzyjne s¹ naj-lepsze do praktycznego zastosowania pozyskiwania wie-dzy w przedsiêbiorstwie, poniewa¿ da³y najlepszy wynik? Czy mo¿na uogólniæ stwierdzenie, ¿e narzêdzia statystycz-ne, ze wzglêdu na fakt, ¿e dzia³aj¹ realizuj¹c metody znane od lat, s¹ najbardziej odpowiednie do pozyskiwania wiedzy
z danych numerycznych? Czy inne zadania pozyskiwania wiedzy: wielopoziomowe uogólnianie danych (ang. multi-level data generalization), odkrywanie podobieñstw w oparciu o wzorce (ang. pattern similarity search), odkry-wanie schematów cie¿ek (ang. mining path traversal pat-terns) z równie dobrymi efektami mo¿na zawsze stosowaæ do otrzymania u¿ytecznej wiedzy? Czy mo¿na z góry przewidzieæ, które z narzêdzi bêdzie najbardziej efektywne w okrelonej sytuacji decyzyjnej? Jak nale¿y zachowaæ siê przy podejmowaniu decyzji o zakupie oprogramowania do realizacji data mining, co wybraæ z bogatej ofert rynkowej w sytuacji konkretnego przedsiêbiorstwa? Czy w ogóle mo¿liwe jest udzielenie sensownej odpowiedzi na te i po-dobne pytania? Jak widaæ, zapytañ jest wiele, ale odpowie-dzi nie s¹ ani ³atwe, ani jednoznaczne, przynajmniej na odpowie- dzi-siejszym etapie rozwoju cywilizacyjnego.
5. Podsumowanie
Przedstawione inteligentne metody odkrywania wiedzy z baz danych s¹ stosowane w praktyce w ró¿nym stopniu, zale¿nie od tego, jak dopracowane s¹ poszczególne dy. I tak np. sieci neuronowe, algorytmy genetyczne, meto-dy rozmyte, metometo-dy indukcyjne i dedukcyjne s¹ mo¿na powiedzieæ szeroko stosowane, a metody temporalne oraz te wywodz¹ce siê z nauk o jêzyku nie doczeka³y siê jeszcze powszechnego u¿ytkowania. Jednak¿e nale¿y ocze-kiwaæ, ¿e maj¹c na uwadze rosn¹c¹ wartoæ wiedzy w dzi-siejszej rzeczywistoci, inteligentne odkrywanie wiedzy z baz danych bêdzie powszechniej stosowane w przedsiê-biorstwach, dostarczaj¹c decydentom u¿ytecznej wiedzy. Literatura:
[1] Baborski A.: Odkrywanie wiedzy dla systemów infor-macyjnych zarz¹dzania, Business Information Systems BIS98, International Conference, Poznañ 1998. [2] Barnu B., Knosala R.: Zastosowanie metody Case
Based Reasoning do szacowania kosztów wytwarza-nia w fazie projektowawytwarza-nia, [w:] Komputerowo Zinte-growane Zarz¹dzanie, red. R. Knosala, tom I, Oficyna Wydawnicza Polskiego Towarzystwa Zarz¹dzania Produkcj¹, Opole 2008.
[3] Beynon-Davis P.: Systemy baz danych, WNT, War-szawa 1998.
[4] Doherty P., Gustafsson J.: Delayed Effects of Actions = Direct Effects + Causal Rules [online]. Linköping Electronic Articles in Computer and Infor-mation Science, Vol. 3, nr 1, 1998. Dostepny w Internecie: http:// www.ep.liu.se/ea/cis/1998/001/ [5] Elmasri R., Navathe S. B.:
Fun-damentals of Database Systems, Addison-Wesley, 2000.
[6] Fayyad M. U.: Editorial in: Data Mining and Knowledge Discove-ry, International Journal, vol. 1, issue 1, 1997.
Tab. 2. Zestawienie porównawcze wyników uzyskanych w przeprowadzonym eksperymencie
[7] Fisher D. H., Schlimmer J. C.: Models of Incremental Learning. A Coupled Research Proposal [online], Vanderbilt University, Technical Report CS-88-05. [Dostêp 10.04.2005]. Dostêpny w Internecie: http:// cswww.vuse.vanderbilt.edu/~dfisher/courses/cs362/ incl/proposal/proposal.html
[8] Galant V., Tyburcy R.: Wprowadzenie do przyrosto-wego uczenia, [w:] Pozyskiwanie wiedzy. Materia³y konferencyjne, red. A. Baborski, Wydawnictwo AE, Wroc³aw 1997.
[9] Goldberg D.: Algorytmy genetyczne i ich zastosowa-nia, Wydawnictwo Naukowo-Techniczne, Warszawa 1995.
[10] Go³uchowski J.: Technologie informatyczne w zarz¹-dzaniu wiedz¹ organizacji, Prace Naukowe Wydaw-nictwo Akademii Ekonomicznej w Katowicach, Kato-wice 2005.
[11] Gwiazda T. D.: Optima_AG. Optymalizator Proble-mów Zarz¹dzania i Biznesu, Wydawnictwa Naukowe Wydzia³u Zarz¹dzania Uniwersytetu Warszawskiego, Warszawa 1999.
[12] Hahn U., Romacker M.: Content management in the SYNDIKATE system How technical documents are automatically transformed to text knowledge bases, Data & Knowledge Engineering vol. 35, No. 2, No-vember 2000.
[13] Hunt E. B., Marin J., Stone P. J.: Experiments in in-duction, Academic Press, 1966.
[14] Iwañski C., Szkatu³a G.: Wybrane metody uczenia maszynowego dla tworzenia regu³ klasyfikacji obiek-tu, PAN IBS, Warszawa 1992.
[15] Karlsson L., Gustafsson J., Doherty P.: Delayed Ef-fects of Actions. Proc. ECAI-98: 13th European
Confe-rence on Artificial Intelligence, Brighton, John Wiley and Sons Ltd., 1998.
[16] Kempa A.: Modelowanie procesów biznesowych z wy-korzystaniem metody case-based reasoning, [w:] Stu-dia i Materia³y Polskiego Stowarzyszenia Zarz¹dza-nia Wiedz¹, red. J. Kacprzyk, L. Drelichowski, PSZW, Bydgoszcz 2005.
[17] Larose D. T.: Odkrywanie wiedzy z danych. Wprowa-dzenie do eksploracji danych, PWN, Warszawa 2006. [18] Meesad P.: Pattern Classification by an Incremental Learning Fuzzy Neural Network, [online]. Niepubli-kowana praca dyplomowa, King Mongkuts Institute of Technology North Bankgok, Bangkok, Tajlandia, 1994 i Faculty of the Graduate College, Oklahoma State University, grudzieñ 1998. [Dostêp 29.12.1998]. Dostêpny w Internecie: http://kmitnb05.kmitnb.ac.th/ ~pym/ilfn.html
[19] Nycz M. (red.): Generowanie wiedzy dla przedsiê-biorstwa. Metody i techniki, Wyd. AE im O. Langego, Wroc³aw 2004.
[20] Nycz M.: Pozyskiwanie wiedzy mened¿erskiej. Podej-cie technologiczne, Wyd. AE im. O. Langego, Wro-c³aw 2008.
[21] Perner P., Petrou M. (eds): Machine Learning and Data Mining in Pattern Recognition, First Internatio-nal Workshop, MLDM99. Leipzig, Germany, Sep-tember 16-18, 1999.
[22] PKDD99 Discovery Challenge. A Collaborative Ef-fort in Knowledge Discovery from Databases [online]. Informacje o bazie. Dostêpny w Internecie: http:// lisp.vse.cz/pkdd99/chall.htm
[23] Quinlan J.R.: Induction of Decision Trees, Machine Learning no 1, 1986.
[24] Shapiro P.G.: Software: Tools for Data Mining and Knowledge Discovery, [Dostêp 20.03.1998]. Dostêp-ny w Internecie: http://info.gte.com/~kdd
[25] Vijayakumar S., Schaal S.: Fast and Efficient Incre-mental Learning for High-dimensional Movement Systems, [w:] Proceedings International Conference on Robotics and Automation (ICRA2000), San Fran-cisco, California, vol. 2, 2000.
INTELLIGENT METHODS OF KNOWLEDGE DISCOVERY FROM DATABASES
Abstract:
Knowledge is more than information; it is the structure so it means specific correlations, statistics rules or other depen-dencies that can be shown in mathematics language or any other natural ones. It is not easy to achieve them because very often we do not even suspect that they exist. They can have a real value that calculated in eve in millions zlotys e.g. when they depict some important market behaviors for a particular sector. Each organization usually collects on its discs which, depending on a given approach, be have either historical value or can be used within an interesting analy-sis, e.g. market analysis. According to P.G. Shapiro, the pioneer of knowledge discovery from databases, the pro-cess of knowledge discovery from databases is not a trivial one of obtaining new, useful for user new knowledge which has been hidden among data and it bas not be known, con-scious, seen by the user.
The article has been devoted to intelligent methods of knowledge discovery from databases. It consists of five parts. Brief introduction presents the subject of this paper: definition and stages of knowledge discovery from databa-ses as well as its location within a decision making process. Next part presents the classification of knowledge discove-ry methods. In the third part the characteristics of intelli-gent methods has been presented .It has been done in the following shape: intelligent methods coming from mathe-matics and statistics, from biological sciences and then from linguistics. Part four covers the results of experiment carried out to compare the efficiency of some intelligent methods in the classification task realization. Short summary ends the paper.
Dr hab. in¿. Ma³gorzata NYCZ, prof. UE Katedra Systemów Sztucznej Inteligencji Instytut Informatyki Ekonomicznej
Wydzia³ Zarz¹dzania, Informatyki i Finansów Uniwersytet Ekonomiczny we Wroc³awiu malgorzata.nycz@ue.wroc.pl