Odkrywanie struktur ukrytych w danych czyli eksploracja danych Final.NET
51
0
0
Pełen tekst
(2) Dwie metody • Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych • Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego w danych trenujących.
(3) Przykład eksploracji danych o naturze statystycznej. Próba 1 wartości zmiennej losowej ‘odległość’ 21 22 36 56 37 69 60 29 30 31. 5 41 29 30 40 35 29 22 29 32. 36 56 49 22 14 51 22 28 11 47. 54 2 8 9 55 62 70 41 46 56. 7 10 42 46 41 41 44 48 17 21. 14 39 35 15 36 15 42 3 69 55. 43 48 23 58 23 65 16 54 68 36. 7 2 35 28 55 15 48 55 4 52. 3 43 41 21 53 29 77 42 76 48. 24 14 28 56 52 26 44 68 28 83. Czy można prognozować procent odległości powyżej 40 km? Próba 2 wartości zmiennej losowej ‘odległość’ 51 3 55 48 15 55 27 36 3 7. 8 11 39 46 39 38 44 48 17 21. 47 74 42 77 30 52 21 37 43 4. 36 21 22 56 38 69 58 29 31 30. 28 56 14 26 51 26 55 67 28 83. 31 30 39 6 38 35 29 22 30 29. 51 67 3 42 19 37 15 35 36 14. 36 56 48 22 15 52 22 28 9 47. 26 60 23 48 43 66 16 54 65 36. 56 44 38 70 59 55 12 8 2 50.
(4) Przykład dyskretnej zmiennej losowej Rzut kostką k : X → {1, 2, 3, 4, 5, 6} Dla i∈ {1, 2, 3, 4, 5, 6} Pr(k = i) = 1/6.
(5) Drugi przykład dyskretnej zmiennej losowej Dzienna sprzedaż jednostek towaru x w pewnym sklepie. sp : X → N={0, 1, 2, . . .}.
(6) Przykład ciągłej zmiennej losowej Odległość miejsca zamówienia taksówki od zajezdni. od : X → R.
(7) Konstrukcja histogramu danych ciągłych • Posortuj dane. • Podziel posortowane dane na przedziały (w przypadku 100 danych powszechną praktyką jest wzięcie od 10 do 15 przedziałów); jeszcze bardziej powszechną praktyką jest branie takich przedziałów, że przypada co najmniej od 5 do 8 danych na przedział. W naszym przypadku po prostu bierzemy przedziały potencjalnie po 7 danych: [0,7) [7,14) [14,21) [21,28) [28,35) [35,42) [42,49) [49,56) [56,63) [63,70) [70,77) [77,84) • oblicz, ile danych wpada do pierwszego przedziału ile danych wpada do drugiego przedziału … ile danych wpada do ostatniego przedziału to jest właśnie histogram początkowy • łączymy przylegające przedziały, do których wpadło mniej niż 5 danych i dostajemy wynikowy histogram..
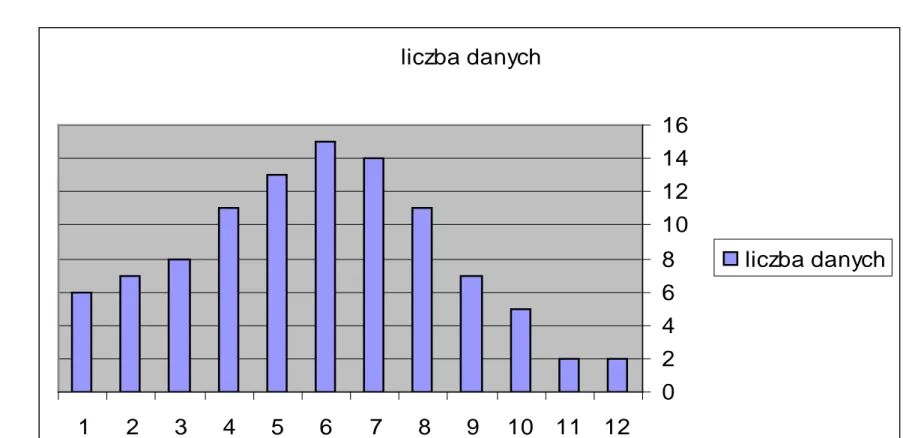
(8) Wynikowe histogramy Nr. przedziału. [lewy kraniec. prawy kraniec). Liczba danych. 0. 0. 7. 6. 1. 7. 14. 7. 2. 14. 21. 8. 3. 21. 28. 11. 4. 28. 35. 13. 5. 35. 42. 15. 6. 42. 49. 14. 7. 49. 56. 11. 8. 56. 63. 7. 9. 63. 70. 5. 10. 70. 77. 2. 11. 77. 84. 2.
(9) Wynikowy histogram po złączeniu przedziałów Nr. przedziału. [lewy kraniec. prawy kraniec). Liczba danych. 0. 0. 7. 6. 1. 7. 14. 7. 2. 14. 21. 8. 3. 21. 28. 11. 4. 28. 35. 13. 5. 35. 42. 15. 6. 42. 49. 14. 7. 49. 56. 11. 8. 56. 63. 7. 9. 63. 999. 9.
(10) Wykres słupkowy histogramu 1 - przedział [0,7) Pasujący do danych rozkład 2 - przedział [7,14) itd. itd. prawdopodobieństwa to prawo ukryte w danych. liczba danych 16 14 12 10 8 6 4 2 0 1. 2. 3. 4. 5. 6. 7. 8. 9. 10 11 12. liczba danych.
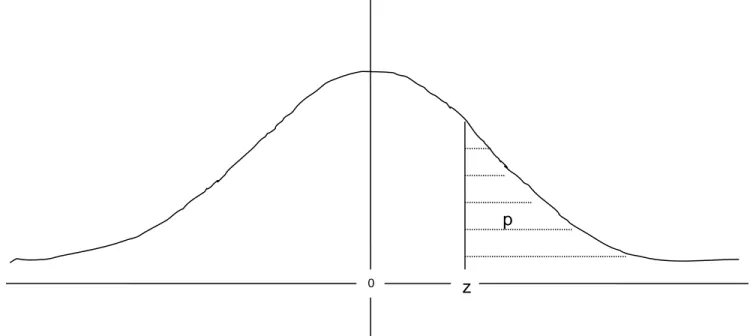
(11) Wykres gęstości standaryzowanego rozkładu normalnego i interpretacja powierzchni pod krzywą Cała powierzchnia pod krzywą = 1 = 100% z=0.1787 – standaryzowana wartość 40-stu p – prawdopodobieństwo, że zmienna losowa przyjmie wartość > 40 Wyliczone z tablic statystycznych p = 0.4291 Prognoza procentu odległości > 40 km – 42.9%. p. 0. z.
(12) Eksploracja danych o naturze kombinatorycznej. Drzewa decyzyjne.
(13) Przykład 1 n. x 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 . .. k 8 10 6 6 5 4 11 20 9 45 1 5 8 8 4 12 10. 16 20 11 12 3 7 22 6 18 90 2 10 5 4 8 24 15. klasyfikacja 1 1 0 1 0 0 1 0 1 1 1 1 0 0 1 ? ?.
(14) Przykład 2 n. x. k. klasyfikacja. 1. 8. 16. 1. 2. 10. 20. 1. 3. 6. 11. 0. 4. 6. 12. 1. 5. 5. 3. 1. 6. 4. 7. 0. 7. 11. 22. 0. 8. 20. 6. 1. 9. 9. 18. 0. 10. 45. 90. 0. 11. 1. 2. 0. 12. 5. 10. 0. 13. 8. 5. 0. 14. 8. 4. 1. 15. 4. 8. 1. 16. 12. 24. ?.
(15) Przykład 3 indeks. x. Wartość. Klasyfikacja. 1. 1. 15. 2. 2. 9. Pierwszy. 3. 3. 4. Pierwszy. 4. 4. 20. Trzeci. 5. 5. 11. Pierwszy. 6. 6. 15. Drugi. 7. 7. 21. Trzeci. 8. 8. 18. Trzeci. 9. 9. 13. Pierwszy. 10. 10. 17. Trzeci. 11. 11. 2. Pierwszy. 12. 12. 12. Pierwszy. 13. 13. 14. Pierwszy. 14. 14. 32. Trzeci. 15. 15. 28. Trzeci. 16. 16. 1. Pierwszy. 17. 17. 10. Pierwszy. 18. 18. 18. ?. Drugi.
(16) Algorytm uczenia wejście: pewien zbiór treningowy . . . działanie . . wyjście: hipoteza ogólnej klasyfikacji dowolnego przykładu do jednej z rozważanych kategorii.
(17) Kolejny przykład – tabela stanów pogody x. aura. temperatura. wilgotność. wiatr. Klasyfikacja. 1. słoneczna. ciepła. duża. słaby. 0. 2. słoneczna. ciepła. duża. silny. 0. 3. pochmurna. ciepła. duża. słaby. 1. 4. deszczowa. umiarkowana. duża. słaby. 1. 5. deszczowa. zimna. normalna. słaby. 1. 6. deszczowa. zimna. normalna. silny. 0. 7. pochmurna. zimna. normalna. silny. 1. 8. słoneczna. umiarkowana. duża. słaby. 0. 9. słoneczna. zimna. normalna. słaby. 1. 10. deszczowa. umiarkowana. normalna. słaby. 1. 11. słoneczna. umiarkowana. normalna. silny. 1. 12. pochmurna. umiarkowana. duża. silny. 1. 13. pochmurna. ciepła. normalna. słaby. 1. 14. deszczowa. umiarkowana. duża. silny. 0. 15. deszczowa. ciepła. duża. słaby. ?.
(18) Testy słoneczna gdy atrybutem aura obiektu x jest słoneczna taura(x) = pochmurna gdy atrybutem aura obiektu x jest pochmurna deszczowa gdy atrybutem aura obiektu x jest deszczowa. dostępne testy :. taura, ttemperatura, twilgotność, twiatr.
(19) Podział zbioru treningowego przez test Każdy test generuje pewien podział zbioru treningowego. Każdy zbiór tego podziału dzieli się na elementy poszczególnych kategorii. Dla testu taura otrzymujemy trzy podziały: (a) podział obiektów x zbioru treningowego z atrybutem aura = słoneczna na te zakwalifikowane do kategorii 0 i na te zakwalifikowane do kategorii 1 (b) podział obiektów x zbioru treningowego z atrybutem aura = pochmurna na te zakwalifikowane do kategorii 0 i na te zakwalifikowane do kategorii 1 (c). podział obiektów x zbioru treningowego z atrybutem aura = deszczowa na te zakwalifikowane do kategorii 0 i na te zakwalifikowane do kategorii 1.
(20) Entropia podziału E =. Σ -pi*log(pi) i przebiegające kategorie.. pi – prawdopodobieństwo wylosowania elementu kategorii nr. i. P1. P2.
(21) Entropia podziału rozpiętego na skończonym zbiorze X = A1∪A2∪ . . . ∪An E = ∑ -(|Ai|/|X|) * log(|Ai|/|X|) 1≤ i ≤ n. Ułamek |Ai|/|X| można interpretować jako prawdopodobieństwo wylosowania elementu kategorii nr. i ze zbioru X..
(22) Entropia testu względem zbioru treningowego Przykład – entropia testu taura ze względu na nasz zbiór treningowy stanów pogody Dla testu taura dostajemy trzy podziały: (a) podział obiektów x zbioru treningowego z atrybutem aura = słoneczna na te zakwalifikowane do kategorii 0 i na te zakwalifikowane do kategorii 1, (b) podział obiektów x zbioru treningowego z atrybutem aura = pochmurna na te zakwalifikowane do kategorii 0 i na te zakwalifikowane do kategorii 1, (c) podział obiektów x zbioru treningowego z atrybutem aura = deszczowa na te zakwalifikowane do kategorii 0 i na te zakwalifikowane do kategorii 1..
(23) Entropia testu względem zbioru treningowego Entropia testu taura względem zbioru treningowego stanów pogody to suma ważona: entropia podziału (a)∗stosunek liczności zbioru na którym rozpięty jest podział (a) do liczności całego zbioru treningowego. +. entropia podziału (b)∗stosunek liczności zbioru na którym rozpięty jest podział (b) do liczności całego zbioru treningowego. +. entropia podziału (c)∗stosunek liczności zbioru na którym rozpięty jest podział (c) do liczności całego zbioru treningowego..
(24) Przykład. t1. t2.
(25) Przykład drzewa decyzyjnego dla zbioru treningowego stanów pogody taura słoneczna {1,2,8,9,11}. {9,11} 1. deszczowa {4,5,6,10,14}. {3,7,12,13} 1. twilgotność normalna. pochmurna. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}. duża {1,2,8}. twiatr słaby {4,5,10}. 0. 1. silny {6,14} 0.
(26) Idea algorytmu indukcji drzew decyzyjnych buduj (T, S, k) :. jeżeli T jest pusty to zwróć liść z wpisaną kategorią domniemaną k w przeciwnym przypadku jeżeli w T jest tylko jedna kategoria to zwróć liść z wpisaną tą jedyną w T kategorią. w przeciwnym przypadku jeżeli S jest pusty to zwróć liść z wpisaną tą kategorią, która jest. najliczniejsza w zbiorze T w przeciwnym przypadku // zbiory S i T są niepuste { zbudowanie węzła n i jego następników, zwrócenie zbudowanego węzła n jako wyniku funkcji buduj – szczegóły na następnym slajdzie};.
(27) Zbudowanie węzła n i jego następników, zwrócenie zbudowanego węzła n jako wyniku funkcji buduj { 1. utwórz kolejny węzeł n; 2. ze zbioru S wybierz, wedle przyjętego kryterium wyboru testu, test t i wpisz go do utworzonego węzła n; 3. jako k przyjmij najliczniejszą w T kategorię; 4. oblicz zbiory treningowe T1, . . ., Tm na które test t dzieli zbiór treningowy T, gdzie m jest liczbą możliwych wartości testu t; 5. dla wszystkich i = 1, . . . ,m wykonaj i-ty następnik węzła n := buduj (Ti, S - {t}, k)//wołanie rekurencyjne 6. zwróć węzeł n jako wynik funkcji buduj; }.
(28) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1.
(29) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1.
(30) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1. słoneczna T1={1,2,8,9,11}, 0 buduj( T1, {ttemperatura, twilgotność, twiatr}, 0).
(31) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1. słoneczna T1={1,2,8,9,11}, 0 twilgotność normalna T11= ={9,11} buduj(T11, {ttemperatura, twiatr}, 1).
(32) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a słoneczna T1={1,2,8,9,11}, 0 twilgotność normalna T11= ={9,11} 1. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1.
(33) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1. słoneczna T1={1,2,8,9,11}, 0 twilgotność normalna T11= ={9,11} 1. duża. T12={1,2,8} buduj(T12, {ttemperatura, twiatr}, 0).
(34) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a słoneczna T1={1,2,8,9,11}, 0 twilgotność normalna T11= ={9,11} 1. duża. T12={1,2,8} 0. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1.
(35) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a słoneczna T1={1,2,8,9,11}, 0. T11= ={9,11} 1. pochmurna T2={3,7,12,13}. twilgotność normalna. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1. buduj(T2,{ttemperatura, twilgotność, twiatr},1). duża. T12={1,2,8} 0.
(36) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a słoneczna T1={1,2,8,9,11}, 0. T2={3,7,12,13}. twilgotność normalna T11= ={9,11} 1. pochmurna. 1. duża. T12={1,2,8} 0. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1.
(37) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a słoneczna T1={1,2,8,9,11}, 0. T2={3,7,12,13}. twilgotność normalna T11= ={9,11} 1. pochmurna. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1 deszczowa T3={4,5,6,10,14}. 1. duża. T12={1,2,8} 0. buduj(T3,{ttemperatura,twilgotność, twiatr}, 1).
(38) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a słoneczna T1={1,2,8,9,11}, 0. T11= ={9,11} 1. deszczowa. pochmurna. T3={4,5,6,10,14}. T2={3,7,12,13}. twilgotność normalna. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1. 1. duża. T12={1,2,8}. twiatr słaby. T31={4,5,10} 0. buduj(T31,{ttemperatura,twilgotność},1).
(39) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a słoneczna T1={1,2,8,9,11}, 0. T11= ={9,11} 1. deszczowa. pochmurna. T3={4,5,6,10,14}. T2={3,7,12,13}. twilgotność normalna. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1. 1. duża. T12={1,2,8}. twiatr słaby. T31={4,5,10} 0. 1.
(40) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a słoneczna T1={1,2,8,9,11}, 0. T11= ={9,11} 1. deszczowa. pochmurna. T3={4,5,6,10,14}. T2={3,7,12,13}. twilgotność normalna. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1. 1. duża. T12={1,2,8}. twiatr słaby. T31={4,5,10} 0. silny T32={6,14}. 1. buduj(T32,{ttemperatura, twilgotność},0).
(41) Wykonanie algorytmu buduj na zbiorze treningowym stanów pogody taur a słoneczna T1={1,2,8,9,11}, 0. T11= ={9,11} 1. deszczowa. pochmurna. T3={4,5,6,10,14}. T2={3,7,12,13}. twilgotność normalna. {1,2,3,4,5,6,7,8,9,10,11,12,13,14}, 1. 1. duża. T12={1,2,8}. twiatr słaby. T31={4,5,10} 0. 1. silny T32={6,14} 0.
(42) Podstawowe Pojęcia zbiór X przykładów – zbiór wszystkich stanów pogody, • zbiór C kategorii pojęcia ocena-pogody, C = {0, 1}, • pojęcie ocena-pogody : X → C , • zbiór hipotez H równy zbiorowi funkcji h : X → C definiowalnych przez pewne drzewo decyzyjne dla przyjętego zbioru dostępnych testów, • błąd hipotezy h względem pojęcia ocena-pogody err(h, ocena-pogody) = |{x∈X | h(x) ≠ ocena-pogody(x) }|/ |X| •.
(43) Formalne definicje Formalne definicje testu, zbioru treningowego, entropii testu względem zbioru treningowego podane są w materiałach dla słuchaczy..
(44) Ocenianie błędu klasyfikatora – walidacja krzyżowa T – pewien zbiór treningowy dla pojęcia c T’ ⊆ T - pewna część zbioru treningowego h – klasyfikator obliczony ze zbioru treningowego T’ Szacunkowy błąd klasyfikacji: zliczona liczba błędnych klasyfikacji na elementach x z T – T’ ---------------------------------------------------------------------------------liczność zbioru T – T’ 1. Należy założyć, że struktura ukryta w zbiorze treningowym T dla pojęcia c dobrze przybliża strukturę ukrytą w całej przestrzeni X i w pojęciu c. Innymi słowy, zbiór T ma być w stosownym sensie reprezentatywny dla przestrzeni X i pojęcia c. 2. Zbiór T’ wybrany do walidacji krzyżowej powinien być reprezentatywny dla zbioru T – struktura ukryta w T’ powinna dobrze przybliżać strukturę ukrytą w T..
(45) Nadmierne dopasowanie Rozważmy pojęcie c : N × N → {0, 1}. 1 gdy k=2n lub k=2n+1 c(n,k) = 0 w przeciwnym przypadku..
(46) Zbiór treningowy T dla pojęcia c dla zilustrowania nadmiernego dopasowania x. n. k. klasyfikacja. 1. 4. 8. 1. 2. 6. 12. 1. 3. 3. 15. 0. 4. 6. 13. 1. 5. 2. 4. 1. 6. 10. 20. 1. 7. 3. 15. 0. 8. 8. 16. 1. 9. 5. 7. 0. 10. 12. 24. 1. 11. 13. 1. 0. 12. 22. 44. 1. 13. 16. 32. 1. 14. 14. 28. 1. 15. 5. 9. 0. 16. 30. 60. 1. 17. 9. 7. 0. 18. 7. 13. 0. 19. 11. 15. 0.
(47) Dostępne testy Tak gdy n, k są parzyste. t1(n,k) = Nie w przeciwnym przypadku. Tak gdy n jest parzysta i k=2n lub n jest nieparzysta t2(n,k) = Nie w przeciwnym przypadku. Tak gdy n jest nieparzysta i k=2n+1 lub n jest parzysta t3(n,k) = Nie w przeciwnym przypadku. Zbiór {Tak, Nie} to zbiór możliwych wartości testów t1, t2, t3..
(48) Dwa klasyfikatory t1. D1: Tak. Nie. 1. 0. D2:. t2 Tak. Nie. t1. 0 Nie. Tak. t3. 1 Tak 1. Nie 0.
(49) Propozycja przeprowadzenia prostych badań 1.. Ściągnij z http://archive.ics.uci.edu/ml/ pliki z oferowanymi tam zbiorami treningowymi. Użyj także przekazanych przez nas plików heart_disease.txt, iris.txt, diabets.txt, wine.txt. 2. Dla każdego z badanych plików napisz program, który 2.1. wczyta zbiór treningowy z pliku 2.2. wśród zadeklarowanych funkcji programu będą funkcje reprezentujące zbiór S dostępnych testów na danych, stosownie do specyfiki konkretnego zbioru treningowego 2.3. program obliczy drzewo decyzyjne z kryterium wyboru testu przez entropię i drzewo decyzyjne z kryterium losowego wyboru testu, 2.4. zgodnie z metodą walidacji krzyżowej zostaną obliczone prawdopodobieństwa błędnej klasyfikacji dla jednego i drugiego drzewa i te prawdopodobieństwa zostaną wyświetlone jako wyniki obliczeń..
(50) Niektóre pola zastosowań metod eksploracji danych • • • •. Automatyczna klasyfikacja plam słonecznych Wsparcie diagnostyki w medycynie Bankowość i marketing Klasyfikacja danych biologicznych . . . i wiele innych.
(51)
(52)
Obraz
Powiązane dokumenty
JeŜeli uczeń wykonuje obliczenia w cm, a wcześniej źle zamienił metry na centymetry, wówczas otrzymuje punkt za realizację tego kryterium, jeŜeli poprawnie obliczył 0,7
Uwaga: Przyznajemy punkt za II kryterium takŜe wtedy, gdy uczeń poprawnie wykonał diagram, a nie otrzymał punktu w kryterium I ( niewłaściwe uporządkowanie).. (południowo-wschodnim
lądowy, a latem ląd się szybciej nagrzewa niż wody morskie (Borneo jest
sprawdzającego wiadomości i umiejętności uczniów klasy I szkoły
Wyłamywanie się z potocznej konsekwencji i reguł, aby podkreślić zamysł treściowy, to stały chwyt „reżyserski” Matejki, bezustannie powtarzająca się jego reguła..
Podsumowując wyniki analiz, należy stwierdzić, że potwierdzona została hipo- teza o zróżnicowanym funkcjonowaniu zadań w wiązkach (z11.1, z11.3 oraz z18.2) ze względu
[r]
Finalne odpowiedzi w postaci liczbowej tworzymy przez połączenie liczb (dodawanie łańcuchów) – uwaga nie wykonujemy operacji dodawania tych liczb, lecz ŁĄCZENIA jak na
!["Mszał Jagiellonów z Jasnej Góry" (wydanie fototypiczne), red. Remigiusz Pośpiech, Opole 2013 : [recenzja]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)